AI 基础认知
# 1、LLM
# 1.1 LLM概念
- 大语言模型(Large Language Model,简称 LLM)。可以说是人工智能的大脑,作为核心推理机,负责理解意图、生成文本和进行逻辑判断。
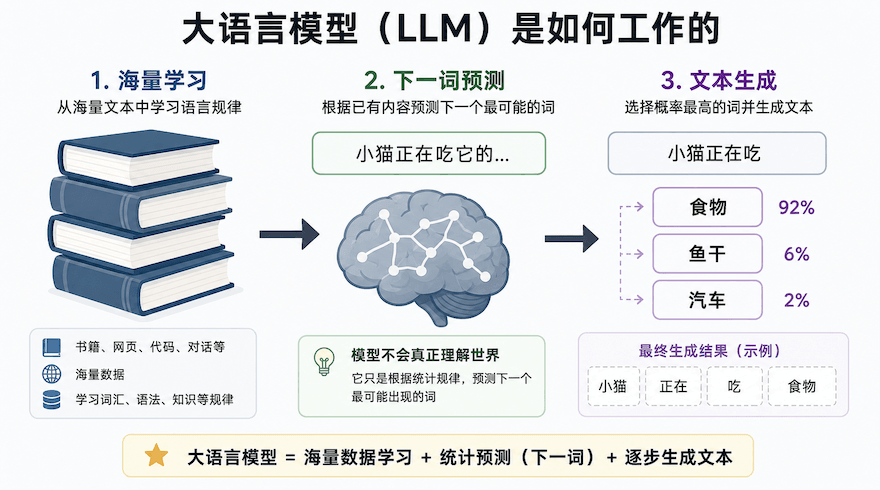
- 大语言模型是一个经过海量文本数据训练的深度学习模型,它能够理解和生成人类语言。大语言模型通过分析互联网上的海量文本,学习语言的统计规律,当收到输入时,根据学到的规律生成最合理的续写。
# 1.2 LLM训练
把大语言模型想象成一个极其用功、记忆力超群的学生
- 学习阶段(训练):它阅读了互联网上几乎所有公开的文本——书籍、文章、网页、代码等(数据量可达万亿单词级别)。在这个过程中,它不是在背诵,而是在学习一套极其复杂的语言规律。
- 应用阶段(推理):当你向它提问或给出指令时,它就会运用学到的规律,一个字接一个字地生成出最合乎逻辑和语境的回答。
# 1.3 LLM的局限性
| 能力 | 说明 | 局限性 |
|---|---|---|
| 知识截止 | 训练数据有截止日期 | 无法获知训练后的新信息 |
| 数学计算 | 能做简单计算 | 复杂计算容易出错 |
| 实时信息 | 需要外部工具辅助 | 本身无法获取实时数据 |
| 事实准确性 | 可能生成错误信息 | 需要事实核查 |
| 长文本处理 | 上下文长度有限制 | 超长文本会丢失信息 |
| 逻辑一致性 | 可能前后矛盾 | 需要仔细设计和验证 |
# 1.4 Transformer 架构
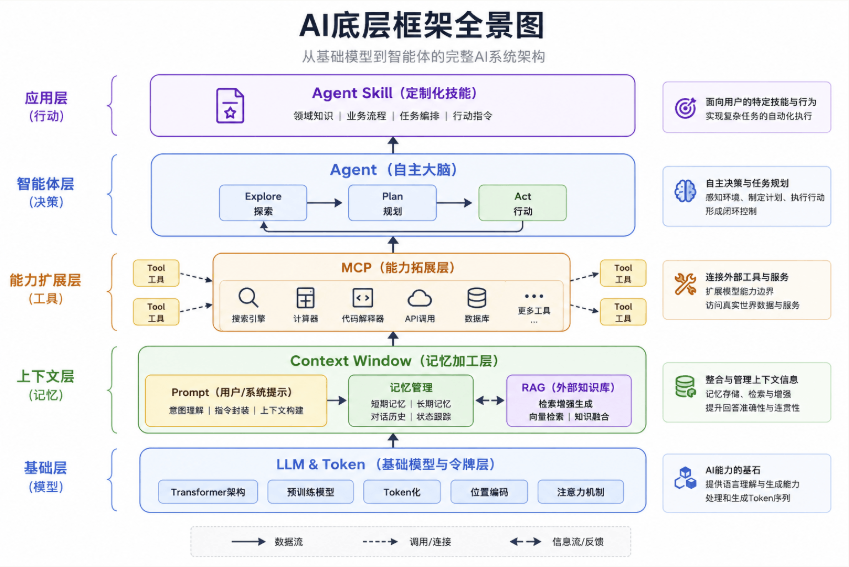
LLM的核心工作原理:Transformer 架构
Transformer 工作方式的核心流程分为三个阶段:
- 输入处理:你的话被拆分成词或字(Token),并转换成计算机能理解的数字(向量)。
- 理解上下文(核心):自注意力机制(Self-Attention)开始工作。它让模型在处理句子中每一个词时,都能权衡句子中所有其他词的重要性。这个过程是并行的,速度极快。
- 生成与循环:模型基于对所有词的理解,计算出概率分布,预测下一个最可能出现的词。选中并输出这个词后,将其作为新的输入,重复整个过程,直到生成完整回答。
![]()
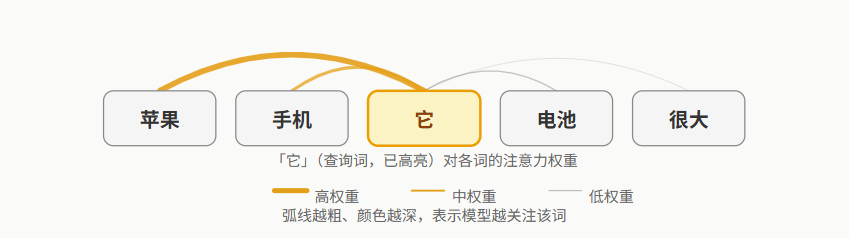
自注意力机制
以句子"苹果的手机它的电池很大"为例,当模型处理它这个词时,自注意力机制会帮助模型判断它与苹果和手机高度相关。下图展示了这一过程中的注意力权重分布:
正是这种能并行处理并深度理解全局上下文的能力,使得基于 Transformer 的 LLM 在语言任务上远超以往技术(如 RNN)。
# 2、Prompt
Prompt概念
Prompt(提示词)是你给 LLM 的输入,是人与 LLM 交互的指令。Prompt 的质量直接决定了回答的质量。
Prompt 通常由以下四个部分组成:

基本原则
- 明确具体: 避免模糊表达。不要说写点关于狗的东西,而应该说用生动活泼的语言,为 6-8 岁儿童写一段 100 字左右的关于金毛寻回犬性格特点的简短介绍。
- 提供上下文:告诉模型你的身份、背景和目标。例如:你是一位经验丰富的 Python 编程导师。请向一个刚学完基本语法的初学者解释什么是列表推导式,并提供一个简单的例子。
- 指定格式:如果需要特定格式的输出,请明确说明,例如:请将以下要点总结为三个 bullet points 或 请以 JSON 格式输出。
- 分步思考(Chain-of-Thought):对于复杂问题,可以在 Prompt 中引导模型逐步推理,例如:请一步一步地分析这个问题,先列出已知条件,再推导中间步骤,最后给出结论。 这种方式能显著提升复杂推理任务的准确率。
总结:将自己的需求列清楚就行,提示词就是我们要学会怎么提问大模型,让它更能理解我们的需求,得到我们想要的高质量问答。
提示词工程
提示词工程(Prompt Engineering)就是一门关于如何构造和精炼你的提示词的艺术和科学,目的是最大化 AI 模型的性能,让它产出更符合你需求的、高质量的输出。
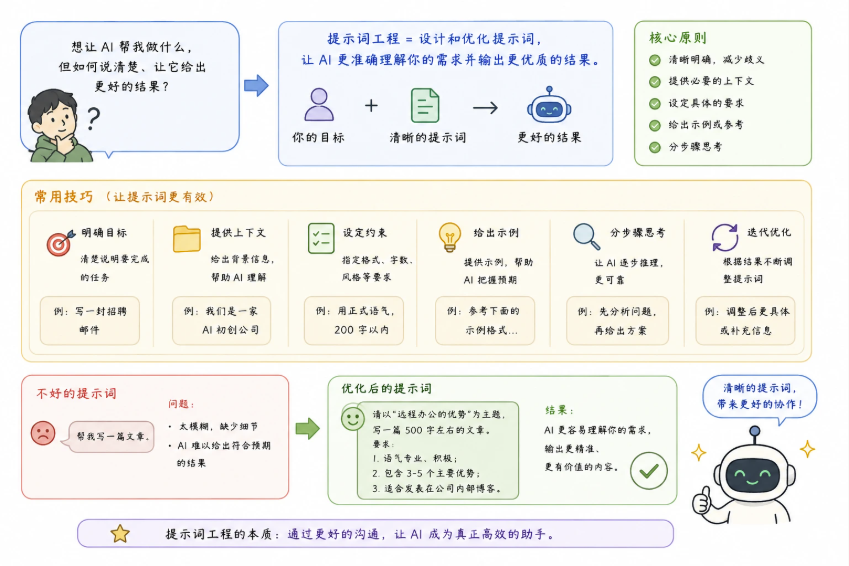
- 提示词(Prompt):就是你输入给 AI 模型(比如大型语言模型 LLM,如 GPT-4 或 Gemini)的指令、问题、或文本输入。
- 工程(Engineering):在这里指的是设计、优化和改进你的输入文本的过程。
为什么需要学习提示词工程?
- 提高准确性——减少 AI 跑题、答非所问的情况
- 节省时间——一次到位,减少来回修改
- 解锁能力——复杂推理、角色扮演、格式输出,都需要特定技巧才能激发
- 降低成本——对开发者而言,好的提示词意味着更少的 API 调用
AI 幻觉
- 语言模型的本质是预测接下来最可能出现的词。当它不知道某个信息时,不会像人一样说我不知道——而是会生成一个听起来合理的回答。
- 这就像一个努力想表现好的实习生,宁可给出一个听起来专业的猜测,也不愿承认自己不知道。
五种防幻觉策略
- 策略 1:明确允许 AI 说我不知道(最简单有效)
如果你不确定某个信息,请直接说"我没有关于这个问题的可靠信息",不要猜测或编造答案。
- 策略 2:限制 AI 只使用你提供的信息
请请只根据 <reference> 标签中的内容回答问题。如果参考资料中没有足够的信息,请回答:"根据提供的资料,无法回答这个问题。"
- 策略 3:先找证据,再给结论
在回答之前,请先在 <evidence> 中找出文档里,直接支持你结论的句子或段落,再在 <answer> 中给出结论。如果找不到支持性证据,就说找不到。
- 策略 4:要求标注置信度
- 对于你回答中的每个关键信息,请在括号内标注置信度:
- (高置信度)= 你非常确定
- (中置信度)= 你有一定把握但不完全确定
- (低置信度)= 你只是猜测,建议用户自行核实
- 策略 5:降低随机性(API 开发者)
在 API 调用中将 temperature 设为 0,让模型的输出更保守、更确定,减少"创意性"发挥带来的错误,适合事实性任务。
# 3、Token
Token 中文称之为 词元 的概念。Token (词元) = AI 能理解的最小文本单位。也就是将我们输入的提示词转为AI能理解的基本单位Token。
比如输入这句话进行拆分:ChatGPT is amazing
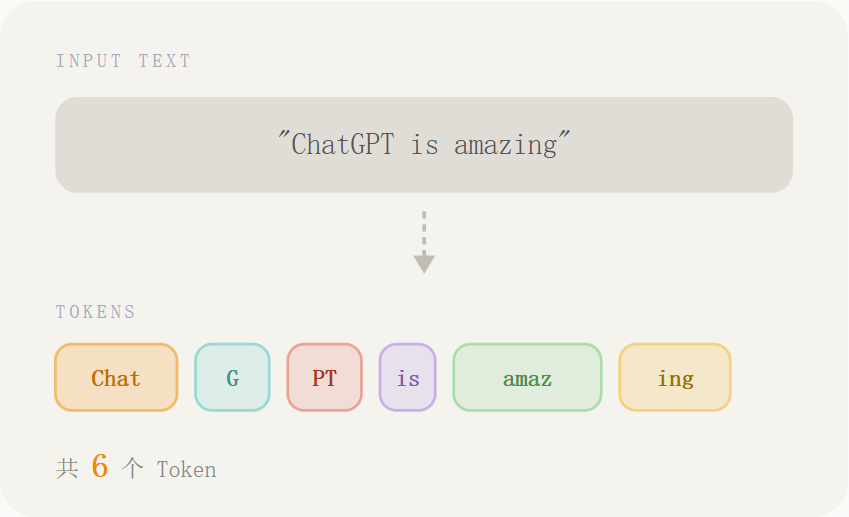
Token 的划分遵循一套特殊的算法,一句话拆成 Token,本质是用子词分词(Subword Tokenization),主流是 BPE(字节对编码),少数用 WordPiece/Unigram,中文、英文逻辑略有不同。
| 文本 | Token 数量 | 说明 |
|---|---|---|
| cat | 1 | 常见词,直接一个 Token |
| unbelievable | 4 | un + believ + able + … |
| ChatGPT | 3 | Chat + G + PT |
| 你好 | 约 2~3 | 中文通常比英文消耗更多 Token |
结论: Token 比单词更细,比字母更粗,是一种灵活的中间单位。
主流算法BPE(GPT/LLaMA/ 通义千问)
- 先按字节切(英文 a-z/A-Z/0-9 / 标点;中文 1 字 ≈ 3 字节)。
- 统计相邻字符对频率,反复合并高频对,直到词表满(如 GPT-2 50257)。
- 特点:能处理任何新词、词表小、泛化强。
- 中文无空格,按字节拆分(UTF-8):1 汉字 = 3 字节 ≈ 2–3 Token。
# 4、Context
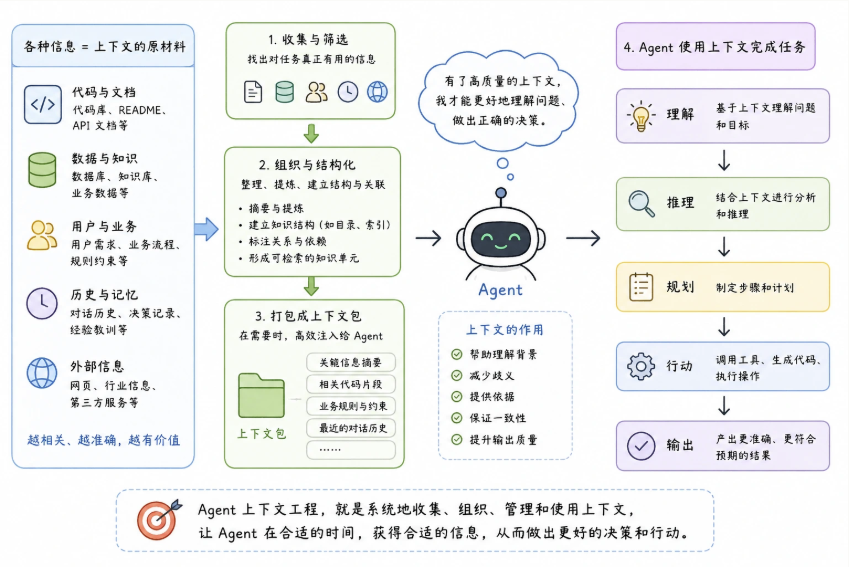
上下文工程(Agent Context Engineering)是系统化设计和优化传递给 AI Agent 的上下文信息的技术实践,它的目标是让 Agent 在有限的上下文窗口内获得最有效的信息,从而提升任务执行的准确性、效率和可靠性。
# 5、Embedding
嵌入(Embedding)是将现实世界的对象(文字、图片、音频等)转换成向量的过程和结果。 这个转换由嵌入模型完成,其核心思想是:语义相近的对象,其向量在空间中的距离也更近。
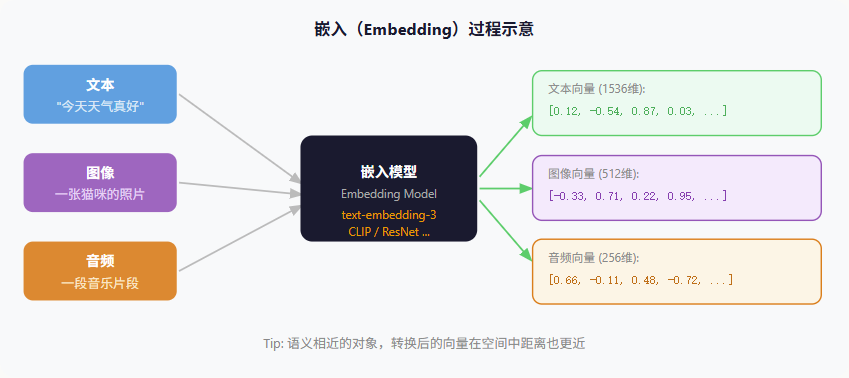
语义近则向量近
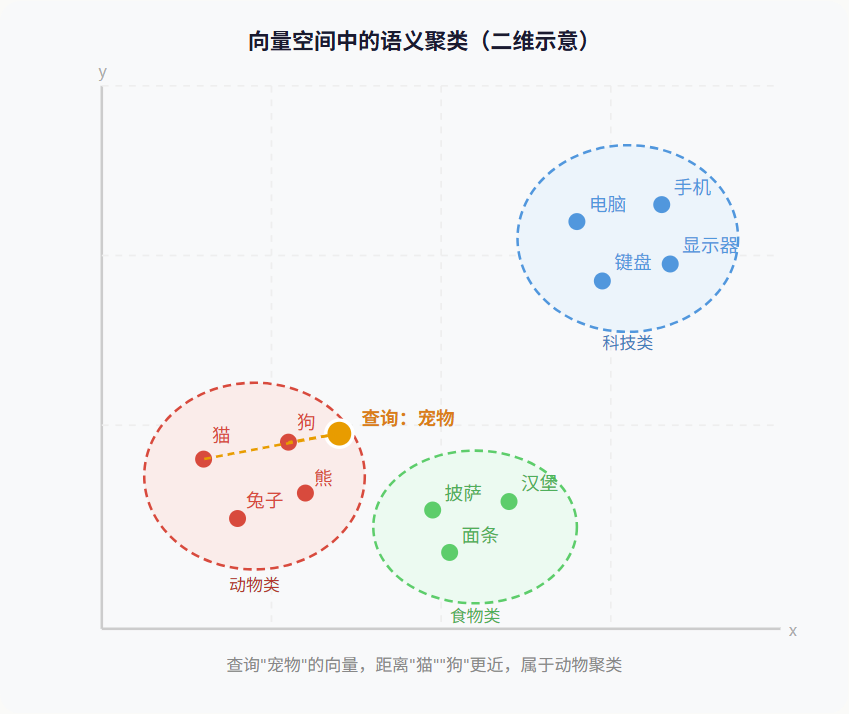
向量数据库(Vector Database)
- 向量数据库(Vector Database)是一种专门用于存储、索引和检索高维向量数据的数据库系统。
- 把意思相近的东西存在一起,并能快速找到和这个最像的那些东西。
- 与传统数据库通过精确匹配来查询(WHERE name = 'Alice')不同,向量数据库通过相似度来查询(找到和这张图最相似的 10 张图)。
相似度计算方法
- 余弦相似度(Cosine Similarity)
余弦相似度衡量两个向量的方向角,忽略长度。这是最常用的方法,尤其适合文本场景。
公式:cosine_similarity(A, B) = (A · B) / (|A| · |B|)
- 结果范围:-1 到 1,值越大越相似
- 适用场景:文本语义搜索、文档相似度
- 欧氏距离(Euclidean Distance)
欧氏距离衡量两点之间的直线距离,距离越小越相似。
公式:d(A, B) = sqrt(Σ(A_i - B_i)^2)
- 结果范围:0 到 ∞,值越小越相似
- 适用场景:图像检索、地理位置相关应用
- 点积(Dot Product)
点积是向量相乘求和,结合了方向和长度信息。
公式:A · B = Σ A_i × B_i
适用场景:推荐系统(向量已归一化时等价于余弦相似度)

# 6、Tools
模型主动识别需求、调用外部工具完成实际操作,不局限纯文本回复。
# 7、MCP
模型上下文协议 ( Model Context protocol ),统一 AI 与工具、数据库、外部服务的通信标准。
# 8、RAG
- RAG(Retrieval-Augmented Generation,检索增强生成)是目前最主流的 LLM 落地架构之一。
- RAG 的核心思想是:让 LLM 在回答问题时,先从外部知识库中检索相关内容,再基于检索结果生成回答,而不是仅依赖模型训练时记住的知识。
- 这解决了 LLM 的两个核心痛点:知识截止日期(模型不知道训练后发生的事)和幻觉问题(模型在不确定时会编造答案)。
RAG 的完整请求流程
一个完整的 RAG 系统由两条流水线组成:离线索引流水线(将文档预处理存入向量库)和在线查询流水线(接收用户问题、检索、生成)。
- 离线阶段将原始文档切分成小块,通过 Embedding 模型转换为向量,存入向量数据库。
- 在线阶段将用户问题同样转换为向量,从数据库中找到最相近的文档块,拼接成上下文交给 LLM 生成答案。
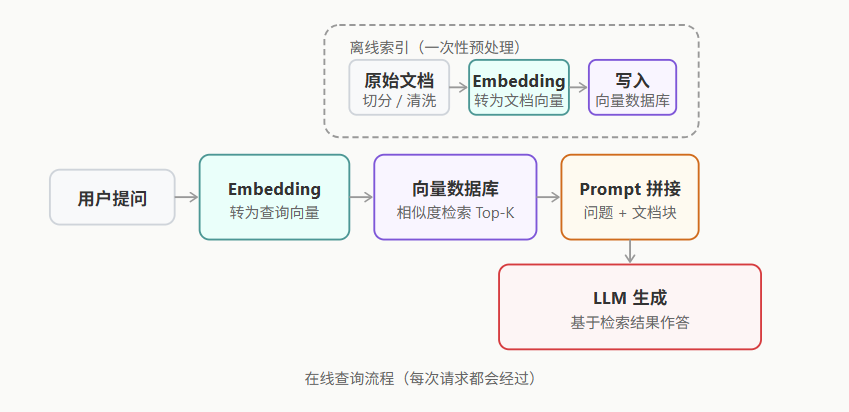
# 9、Memory
为 AI 提供短期会话记忆 + 长期持久记忆,解决上下文遗忘问题。
- 短期记忆:保存当前对话的历史,让 Agent 记得之前说过什么、做过什么。
- 长期记忆:可以存储更持久的信息(例如用户偏好、历史任务结果),供未来任务参考,记录在向量数据库。
# 10、推理与规划
在构建自主 AI Agent 的过程中,如果说大语言模型(LLM)是 Agent 的大脑,工具调用(Tool Use)是手脚,那么推理与规划(Reasoning & Planning)就是将其从简单的问答机升级为自主问题解决者的核心引擎。
复杂的现实任务往往无法通过一次生成(One-pass generation)完成。AI 需要具备拆解目标、逻辑推演、探索路径、自我修正以及调度工具的能力。
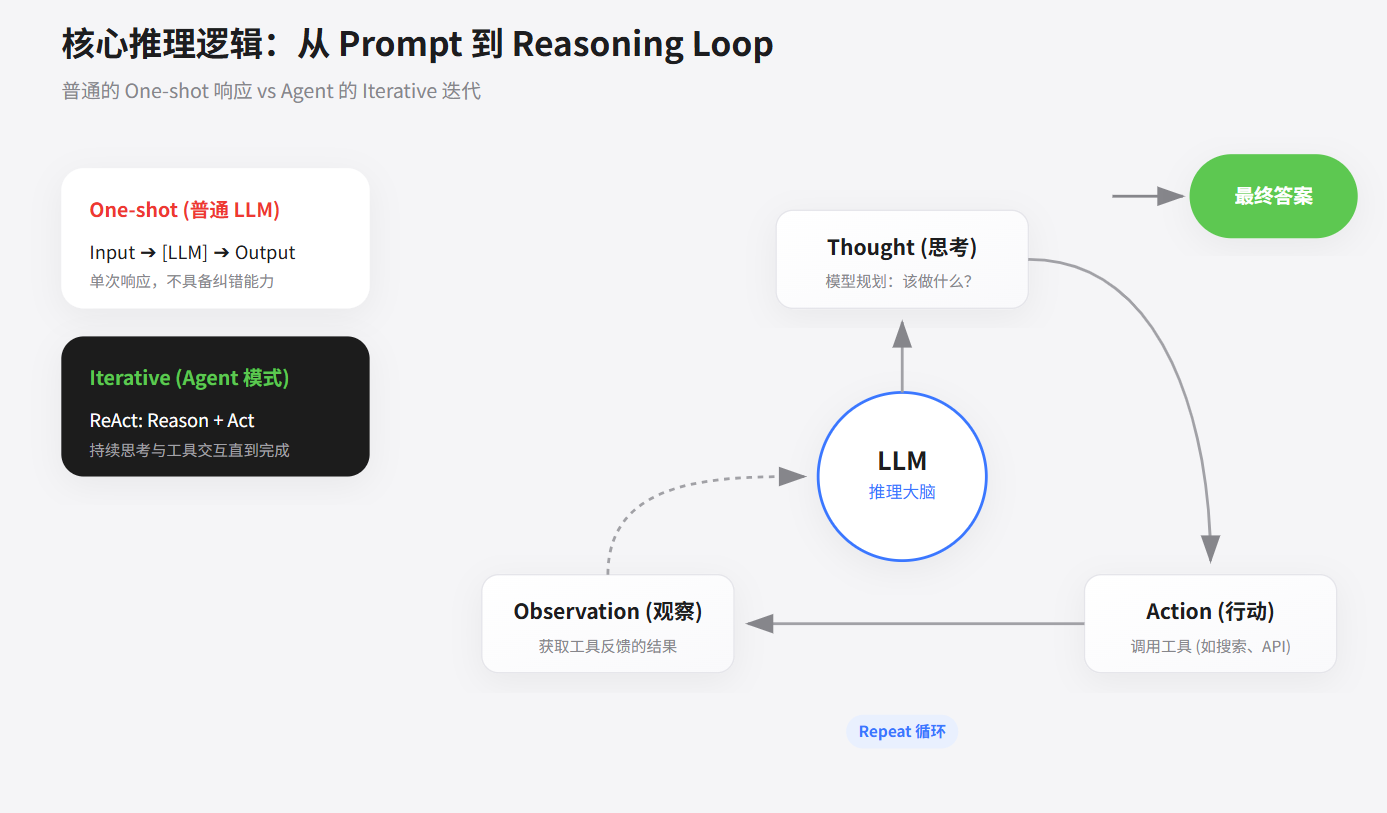
思维链(Chain of Thought, CoT)
思维链(CoT)的核心思想是:强制要求模型在输出最终答案前,先显式地输出中间的推理步骤(Let's think step by step)。这种做法能显著激活模型在复杂数学、逻辑推理和常识问答中的潜力。
ReAct 框架(Reasoning + Acting)
推理 + 行动循环
如果说 CoT 只是在模型内部闭门造车,那么 ReAct(Reason + Act) 则是让模型睁开眼睛看世界。它将内部逻辑推理(Thought)与外部工具交互(Action)交织在一起,形成一个动态的闭环反馈系统。
在 ReAct 范式下,Agent 遵循 Thought(思考) -> Action(行动) -> Observation(观察) 的循环,直到得出最终结论。
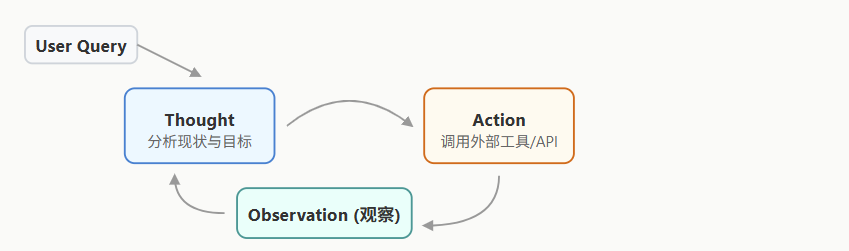
局限性: ReAct 在短期的、步骤清晰的任务中表现优异。但由于整个思维和动作历史都积压在同一个上下文窗口中,当任务链条过长时,极易陷入死循环或因为上下文超载而遗忘初始目标。
Plan-and-Execute(规划先行执行模式)
为了解决 ReAct 在长线任务中的疲软,Plan-and-Execute 将思考和行动进行了解耦,采用了类似人类做大型项目的策略:先出排期表,再挨个干活。
- Planner(规划者):负责接收大目标,生成详细的 Step-by-Step 子任务列表。
- Executor(执行者):负责按顺序执行这些子任务。执行器通常就是一个小型的 ReAct Agent,每次只专注完成当前的一个小目标。
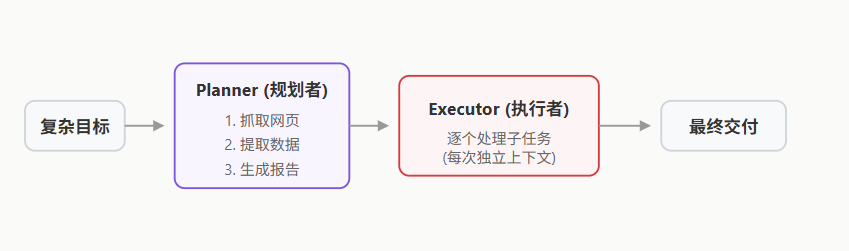
# 11、Agent
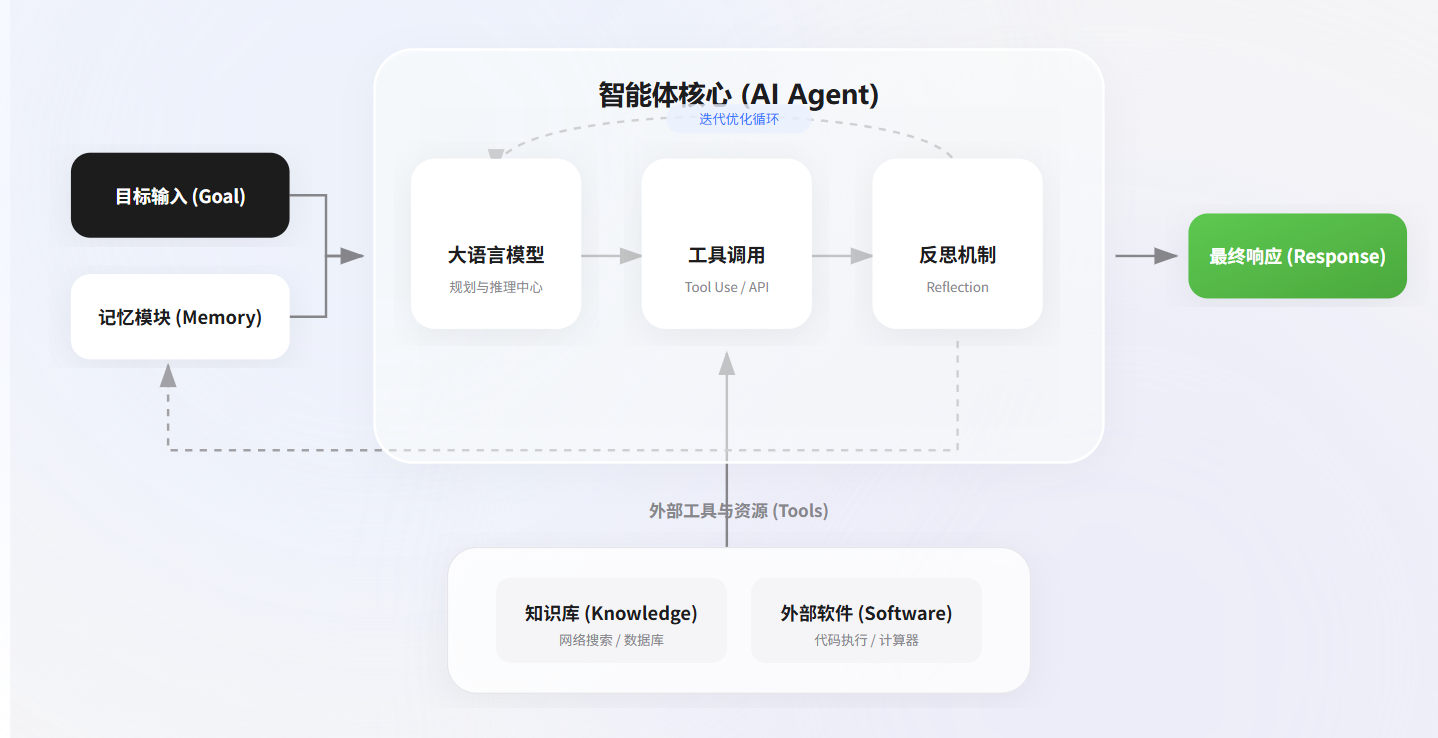
Agent = LLM (大脑) + Planning (规划) + Tool use (执行) + Memory (记忆)。
- LLM (大脑): 作为核心推理机,负责理解意图、生成文本和进行逻辑判断。
- Planning (规划): 能够将复杂的目标(如"帮我策划一场技术沙龙")拆解成可执行的步骤。
- Memory (记忆): 记录对话历史(短期)和存储专业知识库(长期)。
- Tool Use (工具使用): 能够根据需求去查谷歌搜索、读数据库、甚至跑 Python 代码。
Agent 与传统 AI 模型的区别
| 维度 | 传统 AI 模型 | AI Agent |
|---|---|---|
| 交互方式 | 单次输入输出 | 多轮对话、持续交互 |
| 决策能力 | 基于输入直接推理 | 规划、反思、迭代优化 |
| 工具使用 | 无法主动调用外部工具 | 可调用搜索、计算器、API 等 |
| 记忆机制 | 仅限当前上下文 | 短期+长期记忆 |
| 目标导向 | 完成单一预测任务 | 完成复杂目标 |
| 错误处理 | 输出即结束 | 可自我纠错、重试 |
总结:AI Agent 像人一样思考与行动
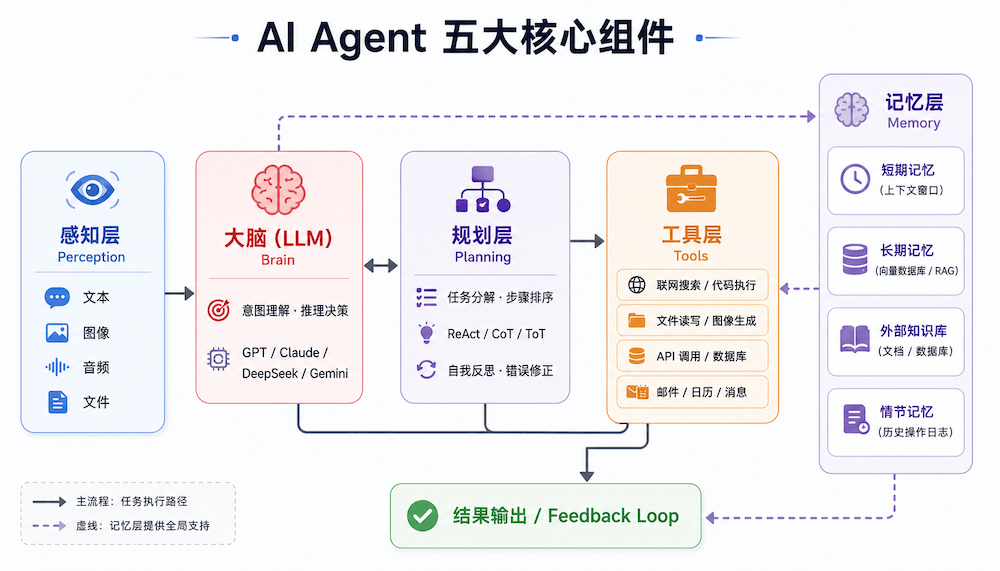
AI Agent 核心组件
四大核心组件:大脑、工具、记忆、规划。
- 大脑:负责听懂点单、判定目标、决定顺序,是餐厅的指挥中心。
- 工具:负责实际动手,包括切配、烹饪、采购等动作,把决策转成可执行操作。
- 记忆:负责记录顾客偏好、当前步骤、已处理内容,保证流程不混乱、不重复。
- 规划:负责把整道菜拆成步骤,确定先后关系,确保任务按流程推进到完成。
当你对 Agent 说:帮我查一下明天北京的天气,如果是雨天,帮我写个提醒发给小王。
Agent 内部是这样运转的:
- 1、感知层:接收到自然语言指令,识别出关键实体"北京"、"明天"、"小王"。
- 2、大脑:听到指令,分析出两个条件任务:查天气,若下雨则发提醒。
- 3、规划:先查天气 → 判断是否下雨 → (如果是) 写提醒 → 发送。
- 4、工具:调用"天气查询工具",获取到结果——明天有雨。
- 5、记忆:去通讯录(记忆库)里查询"小王"的联系方式。
- 6、工具:调用"发送消息工具",把提醒发出去。
- 7、观察:确认消息发送成功,任务完成,循环终止。
# 12、Skills
- Skills 本质上就是教 AI 按固定流程做事的操作说明书,一旦写好,就能像函数一样反复调用。
- 我们可以把 Skills 看成把 某类事情应该怎么专业做 这件事,封装成一个可复用、可自动触发的能力模块。
- Skills 以 Markdown 文件形式存在,不执行功能,而是通过按需、渐进式加载,实现高效且可复用的经验传递。
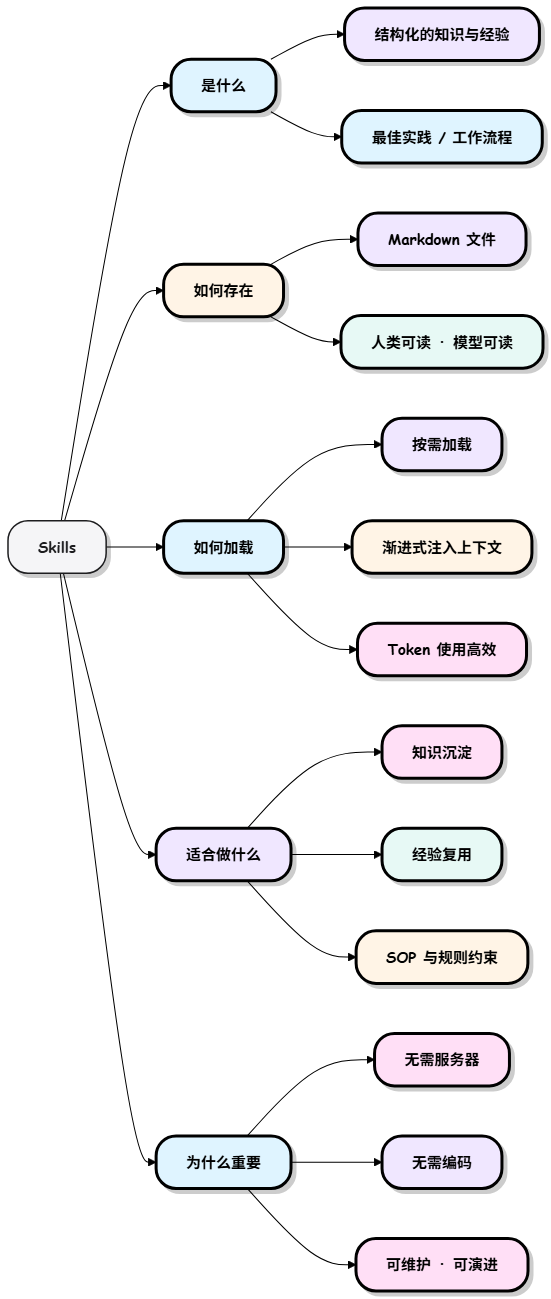
Skills 和传统 Prompt 最大的区别是:按需加载 + 渐进式披露(只在需要时才把厚厚的 SOP 塞进上下文,极大节省 token)。
Skill 的核心结构
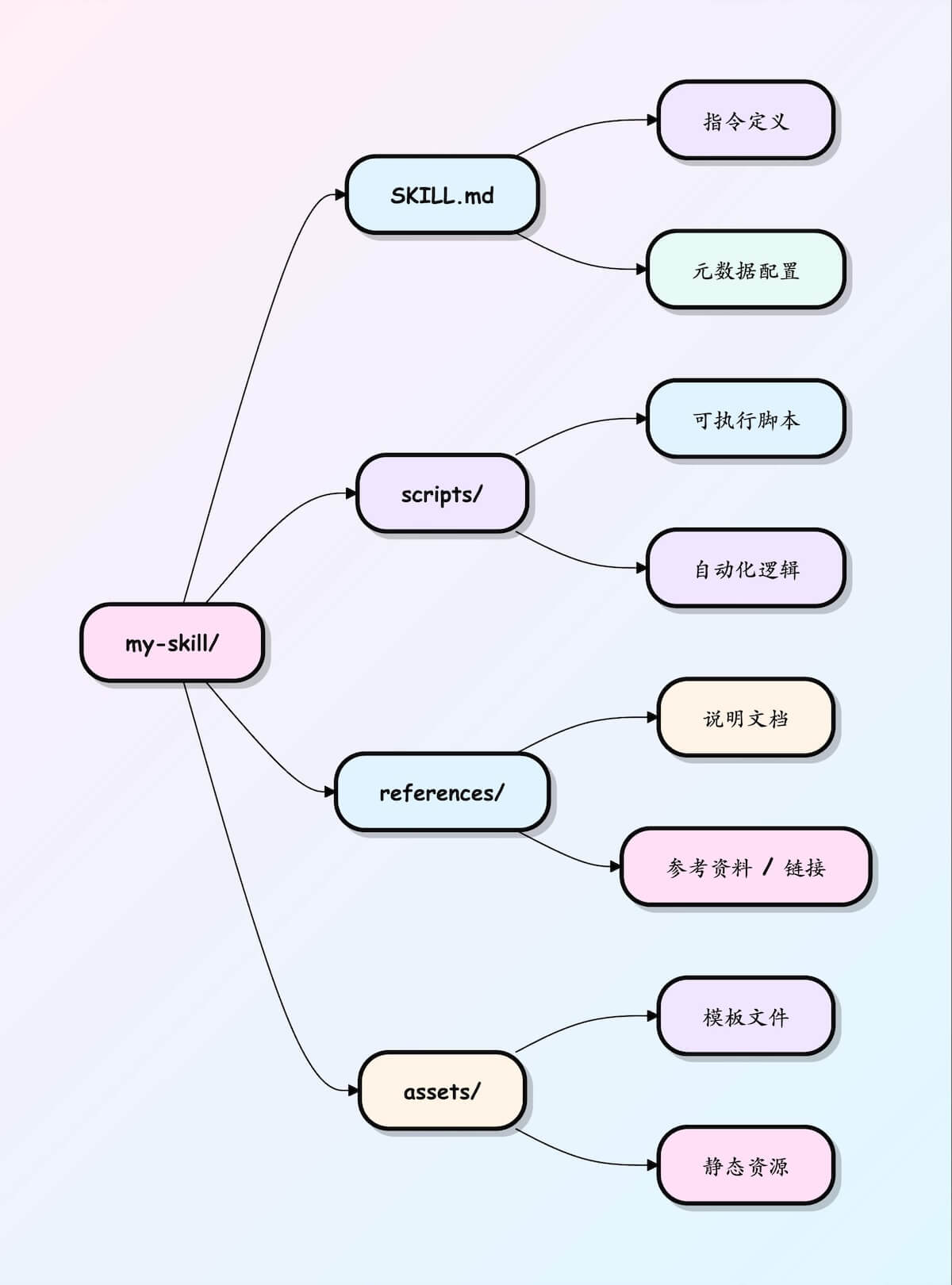
Skills 的核心就是:一个文件夹 + 一个 SKILL.md 文件。
SKILL.md 基本模板:
---
name: pdf-processing
description: 从 PDF 中提取文本和表格,填写表单,并合并文档
---
# PDF 处理
## 使用场景
当需要对 PDF 文件进行操作时使用,例如:
- 提取 PDF 文本或表格数据
- 填写 PDF 表单
- 合并多个 PDF 文件
## 提取文本
- 使用 `pdfplumber` 提取文本型 PDF 内容
- 扫描版 PDF 需配合 OCR 工具
## 填写表单
- 读取 PDF 表单字段
- 按输入数据填充并生成新文件
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
含可选字段示例:
---
name: pdf-processing
description: 从 PDF 中提取文本和表格,填写表单,并合并文档
license: Apache-2.0
metadata:
author: example-org
version: "1.0"
---
2
3
4
5
6
7
8
9
| 字段 | 必需 | 说明 |
|---|---|---|
| name | 是 | Skill 名称,最长 64 字符,只能使用小写字母、数字和 -,且不能以 - 开头或结尾 |
| description | 是 | 功能与使用场景说明,最长 1024 字符,不能为空 |
| license | 否 | 许可证名称或指向随 Skill 附带的许可证文件 |
| compatibility | 否 | 环境与依赖说明(产品、系统包、网络权限等),最长 500 字符 |
| metadata | 否 | 自定义键值对,用于扩展元数据(如作者、版本号) |
| allowed-tools | 否 | 允许使用的工具列表(空格分隔,实验性功能) |
# 13、国内商用大模型