集合详解
目录
# 1、集合概念
集合类关系图
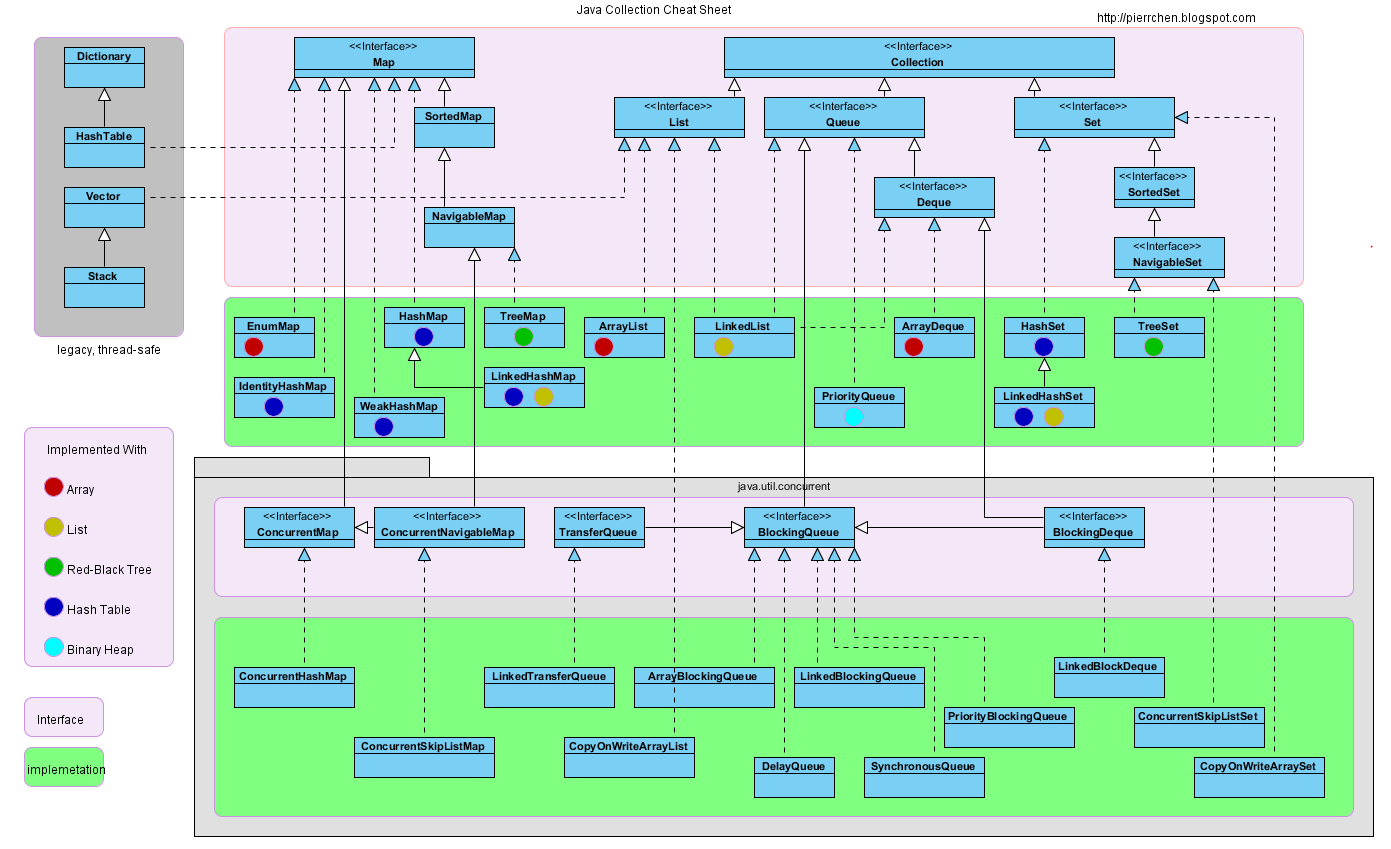
集合概念
- 集合是Java中用于存储和操作一组对象的数据结构。
- 集合也被称为容器,用于存放对象的容器。
- Java容器中只能存储对象,对于基本数据类型(int, long, float, double等),需要包装成对象类型(Integer, Long, Float, Double等)后才能存储到容器中。
- 虽然基本数据类型有时候自动装箱和拆箱会产生一些性能上的开销,但可以简化编程和设计,开销就是值得的。
# 2、集合分类
集合主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射表。
- Collection
- List
- ArrayList【实现类】
- LinkedList【实现类】
- Vector【实现类】
- Stack【实现类,不推荐,使用更高效的ArrayDeque】
- Queue
- PriorityQueue【实现类】
- Deque
- ArrayDeque【实现类】
- Set
- HashSet【实现类】
- LinkedHashSet 【实现类】
- SortedSet
- NavigableSet
- TreeSet【实现类】
- NavigableSet
- HashSet【实现类】
- Map
- HashMap【实现类】
- LinkedHashMap【实现类】
- SortedMap
- NavigableMap
- TreeMap【实现类】
- NavigableMap
- HashTable【实现类】
- Dictionary【实现类】
# 3、Collection
Collection是一个接口,是用来存储一组对象的容器。Collection接口继承了Iterable接口。
Collection定义了对象集合实现类必须实现的方法:
public interface Collection<E> extends Iterable<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
...
}
2
3
4
5
6
7
8
9
10
# 3.1、List
- List是一个接口,它继承了Collection接口,代表了一个有序、可重复的元素序列。
- List接口有多个实现类,包括ArrayList、LinkedList和Vector,每种实现类都有不同的性能特点和适用场景。
# 3.1.1、ArrayList
基于动态数组实现,支持随机访问。
ArrayList<String> list = new ArrayList<>();
list.add("one");
list.add("two");
list.add("three");
System.out.println(list.get(0));
// 输出结果:one
2
3
4
5
6
# 3.1.2、LinkedList
基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
LinkedList<String> list = new LinkedList<>();
list.add("one");
list.add("two");
list.add("three");
System.out.println(list.get(2));
// 输出结果:three
2
3
4
5
6
# 3.1.3、Vector
和 ArrayList 类似,但它是线程安全的。
Vector<String> vector = new Vector<>();
vector.add("one");
vector.add("two");
vector.add("three");
System.out.println(vector.get(2));
// 输出结果:three
2
3
4
5
6
# 3.1.4、List常用方法
| 方法 | 描述说明 |
|---|---|
| add(element) | 将指定的元素添加到列表的末尾。 |
| add(index, element) | 将指定的元素插入到列表的指定位置。 |
| remove(index) | 删除列表中指定位置的元素。 |
| remove(element) | 删除列表中第一次出现的指定元素。 |
| get(index) | 返回指定位置的元素。 |
| set(index, element) | 将指定位置的元素替换为新的元素。 |
| size() | 返回列表中元素的个数。 |
| clear() | 删除列表中的所有元素。 |
| contains(element) | 检查列表是否包含指定的元素。 |
| isEmpty() | 检查列表是否为空。 |
| indexOf(element) | 返回指定元素在列表中第一次出现的位置。 |
| lastIndexOf(element) | 返回指定元素在列表中最后一次出现的位置。 |
| subList(fromIndex, toIndex) | 返回列表中指定范围的子列表。 |
| toArray() | 将列表转换为数组。 |
# 3.2、Queue
- Queue是一个接口,它继承了Collection接口,代表了一种先进先出(FIFO)的数据结构,用于存储和处理元素。
- Queue接口有多个实现类,包括LinkedList和PriorityQueue。
# 3.2.1、LinkedList
LinkedList实现了Queue接口,可以作为队列使用,实现List接口,可以作为列表使用,实现了Deque,可以作为双端队列或者栈使用。
// 创建一个LinkedList对象作为队列
Queue<String> queue = new LinkedList<>();
// 向队列尾部添加元素
queue.offer("Java");
queue.offer("Python");
queue.offer("C++");
// 获取并移除队列头部的元素
String firstElement = queue.poll();
System.out.println("Removed First Element: " + firstElement);
// 获取但不移除队列头部的元素
String peekElement = queue.peek();
System.out.println("Peek First Element: " + peekElement);
// 输出队列中的所有元素
System.out.println("Queue Elements: " + queue);
// 使用迭代器遍历队列的元素
System.out.print("Iterating through Queue: ");
for (String element : queue) {
System.out.print(element + " ");
}
/**
* 输出结果:
* Removed First Element: Java
* Peek First Element: Python
* Queue Elements: [Python, C++]
* Iterating through Queue: Python C++
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 3.2.2、ArrayDeque
ArrayDeque是一个双端队列(deque)实现类,它既可以作为队列使用,也可以作为栈使用。
// 创建一个ArrayDeque对象
ArrayDeque<String> deque = new ArrayDeque<>();
// 添加元素到队列的尾部
deque.addLast("Java");
deque.addLast("Python");
deque.addLast("C++");
// 从队列的头部移除并返回元素
String firstElement = deque.pollFirst();
System.out.println("Removed First Element: " + firstElement);
// 在队列的头部插入元素
deque.addFirst("JavaScript");
// 获取但不移除队列的头部元素
String peekElement = deque.peekFirst();
System.out.println("Peek First Element: " + peekElement);
// 输出队列中的所有元素
System.out.println("Queue Elements: " + deque);
// 使用迭代器遍历队列的元素
System.out.print("Iterating through Queue: ");
for (String element : deque) {
System.out.print(element + " ");
}
/**
* 输出结果:
* Removed First Element: Java
* Peek First Element: JavaScript
* Queue Elements: [JavaScript, Python, C++]
* Iterating through Queue: JavaScript Python C++
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 3.2.3、PriorityQueue
PriorityQueue实现了Queue接口,并且它是一个基于优先级堆(heap)的无界队列。元素按照自然顺序或者指定的比较器顺序进行排序。
// 创建一个优先队列
PriorityQueue<Integer> pq = new PriorityQueue<>();
// 添加元素到优先队列
pq.offer(5);
pq.offer(1);
pq.offer(3);
pq.offer(2);
pq.offer(4);
// 输出整个优先队列
System.out.println("Priority Queue: " + pq);
// 获取并移除队列中的最小元素
int minElement = pq.poll();
System.out.println("Removed Minimum Element: " + minElement);
// 输出优先队列中的元素
System.out.println("Priority Queue: " + pq);
// 获取队列中的最小元素(不移除)
int peekElement = pq.peek();
System.out.println("Peek Minimum Element: " + peekElement);
// 输出优先队列中的元素
System.out.println("Priority Queue: " + pq);
// 遍历并移除优先队列中的所有元素
while (!pq.isEmpty()) {
int element = pq.poll();
System.out.println("Removed Element: " + element);
}
// 输出优先队列是否为空
System.out.println("Priority Queue is Empty: " + pq.isEmpty());
/**
* 输出结果:
* Priority Queue: [1, 2, 3, 5, 4]
* Removed Minimum Element: 1
* Priority Queue: [2, 4, 3, 5]
* Peek Minimum Element: 2
* Priority Queue: [2, 4, 3, 5]
* Removed Element: 2
* Removed Element: 3
* Removed Element: 4
* Removed Element: 5
* Priority Queue is Empty: true
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 3.2.4、Queue常用方法
| 方法 | 描述说明 |
|---|---|
| boolean add(E e) | 在队列的尾部插入一个元素。 如果插入成功,则返回true,如果插入失败(如队列已满),则抛出IllegalStateException。 |
| boolean offer(E e) | 在队列的尾部插入一个元素。 如果插入成功,则返回true,如果插入失败(如队列已满),则返回false。 |
| E remove() | 移除并返回队列头部的元素。 如果队列为空,该方法将抛出NoSuchElementException。 |
| E poll() | 移除并返回队列头部的元素。 如果队列为空,该方法将返回null。 |
| E element() | 返回队列头部的元素,但不移除此元素。 如果队列为空,该方法将抛出NoSuchElementException。 |
| E peek() | 返回队列头部的元素,但不移除此元素。 如果队列为空,该方法将返回null。 |
# 3.3、Set
- Set是一个接口,它继承了Collection接口,用于存储不重复的元素,但元素的顺序是不保证的。
- Set的实现类,常用的有HashSet、LinkedHashSet和TreeSet。
# 3.3.1、HashSet
HashSet使用哈希表实现,元素的存储顺序是不确定的。添加、删除和查找操作的时间复杂度平均为O(1),是最常用的Set实现类。
Set<String> set = new HashSet<>();
set.add("apple");
set.add("banana");
set.add("apple"); // 忽略重复元素
set.remove("banana");
System.out.println(set.contains("apple")); // 输出:true
System.out.println(set.size()); // 输出:1
System.out.println(set.isEmpty()); // 输出:false
for (String element : set) {
System.out.println(element);
}
/**
* 输出结果:
* apple
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 3.3.2、LinkedHashSet
LinkedHashSet在HashSet的基础上,每个元素维护了一个指向前一个和后一个元素的指针,因此在遍历时可以保证元素的插入顺序,即按照元素添加的顺序进行遍历。
Set<Integer> set = new LinkedHashSet<>();
set.add(3);
set.add(1);
set.add(2);
for (int element : set) {
System.out.println(element); // 输出:3, 1, 2(按照插入顺序)
}
2
3
4
5
6
7
8
# 3.3.3、TreeSet
TreeSet内部使用红黑树实现,元素根据自然顺序或者指定的Comparator进行排序。添加、删除和查找操作的时间复杂度为O(log n),遍历时按照元素的顺序进行。
Set<Integer> set = new TreeSet<>();
set.add(3);
set.add(1);
set.add(2);
for (int element : set) {
System.out.println(element); // 输出:1, 2, 3(按照元素的自然顺序)
}
2
3
4
5
6
7
8
# 3.3.4、Set的注意点
需要注意的是,存储在Set中的元素必须正确实现hashCode()和equals()方法,以确保Set可以正确地判断元素的重复性。比如,我们自定义一个Person类,并在Set中使用它:
class Person {
private String name;
private int age;
// 构造方法、getter和setter等省略
@Override
public int hashCode() {
// 根据name和age计算hashCode
return Objects.hash(name, age);
}
@Override
public boolean equals(Object obj) {
// 比较name和age是否相等
if (this == obj) {
return true;
}
if (obj == null || getClass() != obj.getClass()) {
return false;
}
Person other = (Person) obj;
return Objects.equals(name, other.name) && age == other.age;
}
}
Set<Person> set = new HashSet<>();
Person person1 = new Person("Alice", 20);
Person person2 = new Person("Bob", 30);
Person person3 = new Person("Alice", 20);
set.add(person1);
set.add(person2);
set.add(person3); // 忽略重复元素
System.out.println(set.size()); // 输出:2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 3.3.5、Set常用方法
| 方法 | 描述说明 |
|---|---|
| add(element) | 将指定的元素添加到集合中。 |
| remove(element) | 从集合中删除指定的元素。 |
| contains(element) | 检查集合是否包含指定的元素。 |
| size() | 返回集合中元素的个数。 |
| clear() | 删除集合中的所有元素。 |
| isEmpty() | 检查集合是否为空。 |
| iterator() | 返回一个用于遍历集合的迭代器。 |
| toArray() | 将集合转换为数组。 |
# 4、Map
- Map是一种键值对的数据结构,用于存储和操作键值对。每个键值对都由一个键和一个值组成,键是唯一的,但值可以重复。
- Map的实现类,常用的有HashMap、LinkedHashMap、TreeMap和HashTable。
# 4.1、HashMap
HashMap使用哈希表实现,键的顺序是不确定的。添加、删除和查找操作的时间复杂度平均为O(1),是最常用的Map实现类。
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("one", 1);
map.put("two", 2);
map.put("three", 3);
System.out.println(map.get("one")); // 输出 1
2
3
4
5
# 4.2、LinkedHashMap
LinkedHashMap在HashMap的基础上,增加了一个双向链表来维护键的插入顺序。因此,在遍历时可以按照键的插入顺序或者访问顺序进行遍历。
Map<String, Integer> map = new LinkedHashMap<String, Integer>();
map.put("one", 1);
map.put("two", 2);
map.put("three", 3);
map.keySet().forEach(System.out::println); // 输出 one two three
2
3
4
5
# 4.3、TreeMap
TreeMap内部使用红黑树实现,键根据自然顺序或者指定的Comparator进行排序。添加、删除和查找操作的时间复杂度为O(log n),遍历时按照键的顺序进行。
Map<String, Integer> map = new TreeMap<String, Integer>();
map.put("one", 1);
map.put("two", 2);
map.put("three", 3);
map.keySet().forEach(System.out::println); // 输出 one three two
2
3
4
5
# 4.4、HashTable
HashTable类似于HashMap,是同步的。HashTable不允许null键或值。HashTable的键值是无序的,它和HashMap的不同在于它是线程安全的。
Hashtable<String, Integer> table = new Hashtable<>();
table.put("one", 1);
table.put("two", 2);
table.put("three", 3);
System.out.println(table.get("one")); // 输出 1
2
3
4
5
# 4.5、Map常用方法
| 方法 | 描述说明 |
|---|---|
| put(key, value) | 向Map中添加一个键值对,如果键已经存在,则会覆盖对应的值。 |
| get(key) | 返回与指定键关联的值,如果键不存在,则返回null。 |
| remove(key) | 从Map中删除与指定键关联的键值对,如果键不存在,则不进行任何操作。 |
| containsKey(key) | 检查Map中是否包含指定的键。 |
| containsValue(value) | 检查Map中是否包含指定的值。 |
| size() | 返回Map中键值对的数量。 |
| isEmpty() | 检查Map是否为空。 |
| keySet() | 返回一个包含所有键的Set集合。 |
| values() | 返回一个包含所有值的Collection集合。 |
| entrySet() | 返回一个包含所有键值对的Set集合,每个键值对都是一个Map.Entry对象。 |
| putAll(map) | 将指定Map中的所有键值对添加到当前Map中。 |
| clear() | 清空Map中的所有键值对。 |
# 5、如何选择集合类
以下是一些常见的集合类选择方式
| 方法 | 描述说明 |
|---|---|
| ArrayList | 适用于需要频繁访问随机元素的情况,不适合频繁插入和删除操作。 |
| LinkedList | 适用于需要频繁插入和删除元素的情况,不适合频繁访问随机元素。 |
| HashSet | 适用于需要快速查找元素的情况,不保证元素的顺序。 |
| TreeSet | 适用于需要对元素进行排序的情况,元素默认按照自然排序进行排序。 |
| HashMap | 适用于需要快速查找键值对的情况,不保证键值对的顺序。 |
| TreeMap | 适用于需要按照键对键值对进行排序的情况。 |
| LinkedHashMap | 适用于需要保持插入元素的顺序的情况。 |
| PriorityQueue | 适用于需要维护一组元素的大小顺序的情况。 |