HashMap和HashSet源码解析
# 1、HashMap概念
- HashMap实现了Map接口,是一种使用键值对存储数据的数据结构。
- HashMap允许null作为键和值。
- HashMap不保证元素的顺序,特别是不保证顺序恒定。
- HashMap是基于哈希表实现的数据结构,具有快速的插入、删除和查找操作。
- HashMap使用了一个数组来实现哈希表,每个位置被称为桶(bucket)。
- 每个桶又是一个链表的头节点,用于处理哈希冲突(即两个不同的键哈希值相同)的情况。
- 当链表长度超过阈值(默认为8)时,链表将转化为红黑树,以提高查找效率。
- 当链表长度回落到阈值以下时,红黑树将转化为链表。
- JDK8才引入的红黑树,JDK8之前底层结构只有数组+链表。
HashMap数据结构图
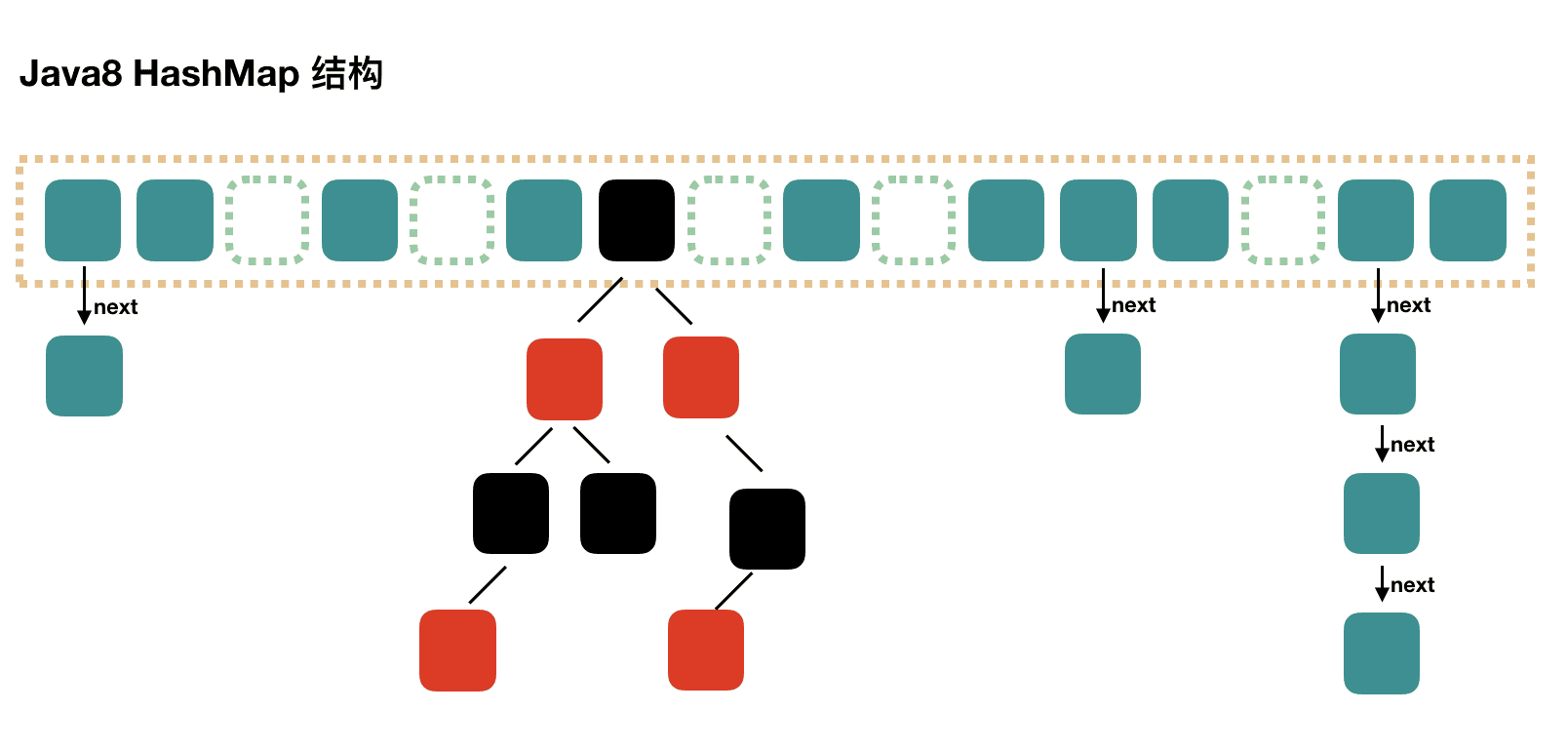
HashMap是一种使用键值对存储数据的数据结构,底层实现为数组+(链表或红黑树)
# 2、哈希
# 2.1、哈希概念
对于哈希,第一个次接触可能会很混乱,我们先把以下这几个重要概念先讲清楚:哈希、哈希值、哈希函数、哈希算法、哈希表、HashMap、Hashtable。
- 哈希
- 哈希(Hash) 是一种将任意长度的数据映射为固定长度的数据的技术。
- 哈希是一个概念,它还有另外一种说法叫做散列。我个人理解就是以特定的规则分散到指定的区域。
案例
将100本书,按照他们的编号(每个编号长度不固定,比如45756454、45622231211),以特定的规则(算法),分配到10个书架上(书架编号1到10)。
具体为45756454 -> 6,那么就将书本编号为45756454放到6号书架上。
- 哈希值
- 哈希值就是通过哈希算法得到的一个值,比如上述案例中
45756454 -> 6,这个6就是哈希值。 - 哈希值通常是一个数字或一个固定长度的字节数组。
- 哈希函数
- 哈希函数是用于实现哈希的算法,它将输入数据转换为哈希值。
- 一个函数方法,将原值输入,返回一个固定长度的哈希值。
简单案例
public int hashCode(int value) {
return value % 10 + 1;
}
2
3
对输入的数值求10以内的余数+1,就得到了1到10的哈希值。这只是个简单的案例,实际中哈希函数要复杂的多。
- 哈希算法
- 就是哈希函数中的实现,比如上述的
value % 10 + 1。 - 后面会详解哈希算法和它的特性。这里只做简单说明。
- 哈希表
- 哈希表是一种数据结构的概念。
- 哈希表,又称散列表,其通过建立键 key 与值 value 之间的映射,实现高效的元素查询。
哈希表结构

能通过key值找到value的一种数据结构,我们把它叫做哈希表结构,也就是哈希表。
- HashMap
- HashMap是哈希表的一种实现,也就是我们本章会详解的内容。
- HashMap概念我们在前面已经讲过,这里不再赘述。
HashMap是哈希表的一种实现方式,也就是哈希表的一种体现。
- Hashtable
- Hashtable也是Java中一种线程安全的哈希表实现类。
- Java中的Hashtable是一个类,是哈希表的一种实现,虽然名字都是哈希表,但是一个是概念,一个时实现。
Hashtable类本章后面也会介绍一下。
# 2.2、哈希表
- 哈希表,又称散列表,其通过建立键 key 与值 value 之间的映射,实现高效的元素查询。
哈希表结构
- 哈希表是一种数据结构的概念。
- 哈希表的增删改查操作的时间复杂度都是O(1)。
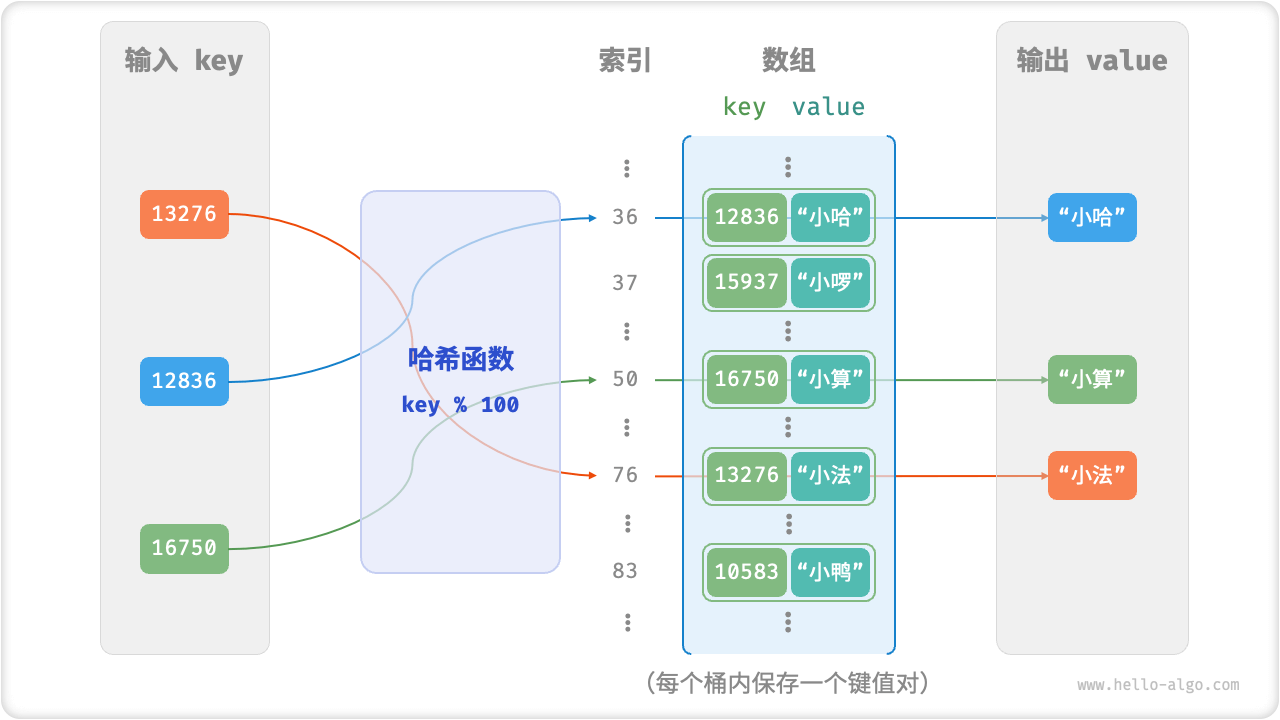
- 数组实现哈希表
- 定义哈希表结构:我们将数组中的每个空位称为桶(bucket),每个桶可存储一个键值对。
- 确认桶位置(散列):通过哈希算法 hash() 计算得到哈希值。哈希值作为桶下标。
- 哈希表实现还需要提供一些方法:查询、插入、删除、获取所有键值对、获取所有键、获取所有值等。
数组实现哈希表结构图

散列过程
- 哈希表简单实现代码
/* 键值对 */
class Pair {
public int key;
public String val;
public Pair(int key, String val) {
this.key = key;
this.val = val;
}
}
/* 基于数组简易实现的哈希表 */
class ArrayHashMap {
private List<Pair> buckets;
public ArrayHashMap() {
// 初始化数组,包含 100 个桶
buckets = new ArrayList<>();
for (int i = 0; i < 100; i++) {
buckets.add(null);
}
}
/* 哈希函数 */
private int hashFunc(int key) {
int index = key % 100;
return index;
}
/* 查询操作 */
public String get(int key) {
int index = hashFunc(key);
Pair pair = buckets.get(index);
if (pair == null)
return null;
return pair.val;
}
/* 添加操作 */
public void put(int key, String val) {
Pair pair = new Pair(key, val);
int index = hashFunc(key);
buckets.set(index, pair);
}
/* 删除操作 */
public void remove(int key) {
int index = hashFunc(key);
// 置为 null ,代表删除
buckets.set(index, null);
}
/* 获取所有键值对 */
public List<Pair> pairSet() {
List<Pair> pairSet = new ArrayList<>();
for (Pair pair : buckets) {
if (pair != null)
pairSet.add(pair);
}
return pairSet;
}
/* 获取所有键 */
public List<Integer> keySet() {
List<Integer> keySet = new ArrayList<>();
for (Pair pair : buckets) {
if (pair != null)
keySet.add(pair.key);
}
return keySet;
}
/* 获取所有值 */
public List<String> valueSet() {
List<String> valueSet = new ArrayList<>();
for (Pair pair : buckets) {
if (pair != null)
valueSet.add(pair.val);
}
return valueSet;
}
/* 打印哈希表 */
public void print() {
for (Pair kv : pairSet()) {
System.out.println(kv.key + " -> " + kv.val);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
# 2.3、哈希冲突
哈希表是数组实现,数组空间有限,所以哈希函数计算的哈希值理论上是会有重复的。也就是一定存在多个输入对应相同输出的情况。多个值会落在同一个桶中,这就是哈希冲突。
哈希冲突
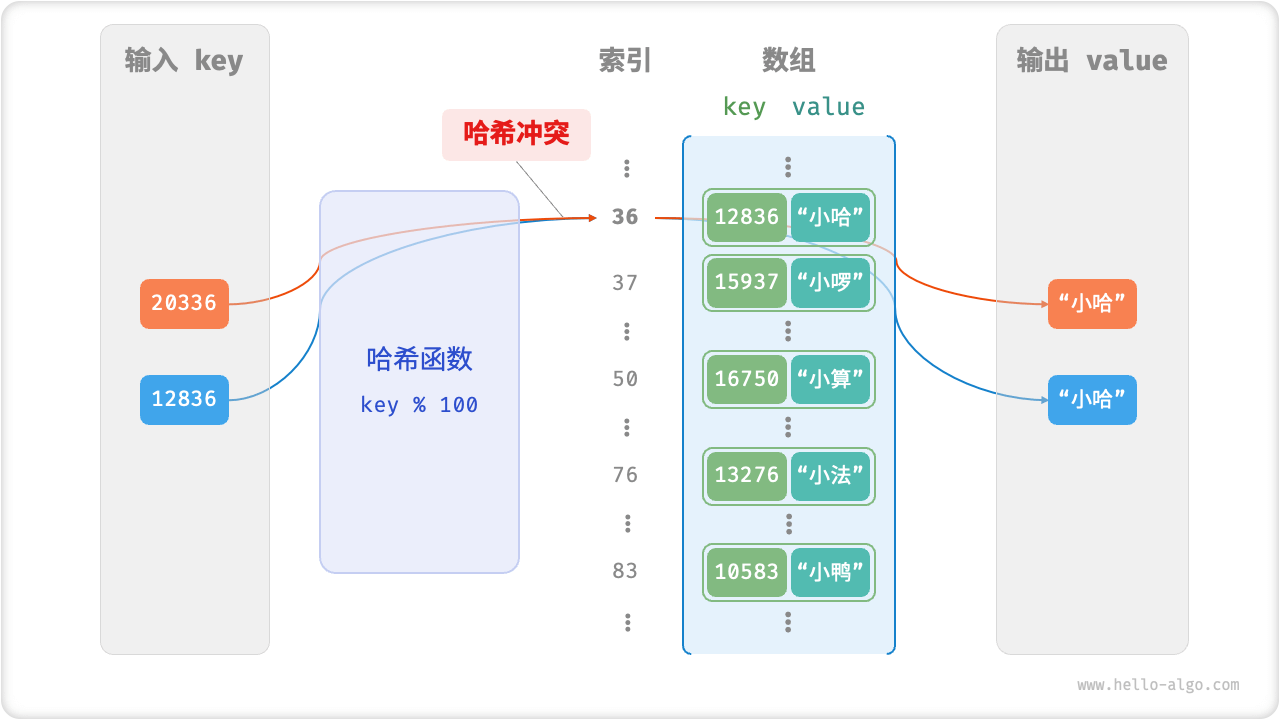
那我们要如何解决哈希冲突呢?
主要方式有多种:扩容方式、链式地址、开放寻址。
- 扩容方式
当发生哈希冲突时,将数组扩大,也就是重新计算每个值对应的桶下标。实现上是新建一个原来2倍的哈希表,将旧的哈希表中的值重新计算桶下标后,填入新的哈希表中。这样的扩容方式,在数据量较大时,会非常消耗时间。但哈希冲突就会消失。但无限的扩容不是一个好的选择,因为数据量越大,需要的空间就越大。
扩容流程

- 链式地址
将单个元素转换为链表,将键值对作为链表节点,将所有发生冲突的键值对都存储在同一链表中。
链式地址结构

链式地址局限性
- 占用空间增大,链表包含节点指针,它相比数组更加耗费内存空间。
- 查询效率降低,因为需要线性遍历链表来查找对应元素。
- 开放寻址
- 线性探测:采用固定步长的线性搜索来进行探测,其操作方法与普通哈希表有所不同。
- 平方探测:当发生冲突时,平方探测不是简单地跳过一个固定的步数,而是跳过探测次数的平方的步数,即 1、4、9 步。
- 多次哈希:多次哈希使用多个哈希函数进行探测。
线性探测
采用固定步长的线性搜索来进行探测。
- 插入元素:通过哈希函数计算桶索引,若发现桶内已有元素,则从冲突位置向后线性遍历(步长通常为 ),直至找到空桶,将元素插入其中。
- 查找元素:若发现哈希冲突,则使用相同步长向后线性遍历,直到找到对应元素,返回
value即可;如果遇到空桶,说明目标元素不在哈希表中,返回null。
固定步长的线性探测过程
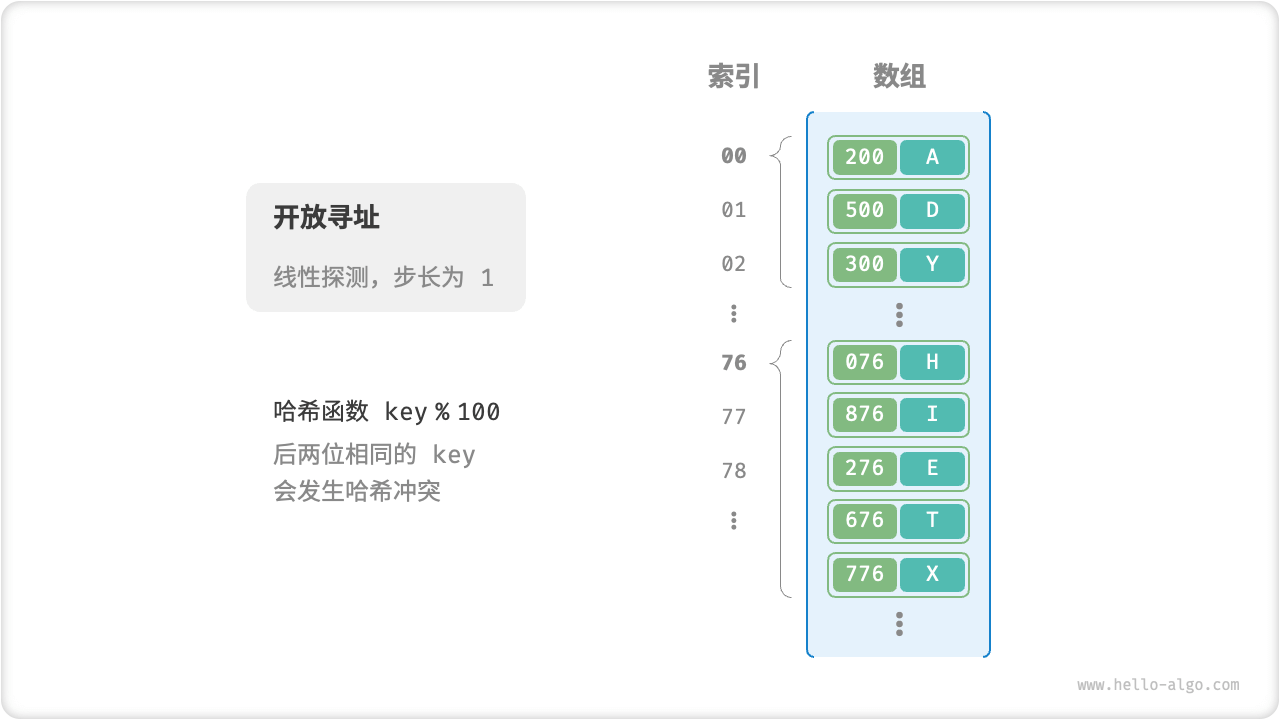
最后两位相同的 key 都会被映射到相同的桶。再通过线性探测,它们被依次存储在该桶以及之下的桶中。
线性探测容易产生聚集现象。数组中连续被占用的位置越长,这些连续位置发生哈希冲突的可能性越大,从而进一步促使该位置的聚堆生长,形成恶性循环,最终导致增删查改操作效率劣化。
平方探测
平方探测就是在线性探测的基础之上,只是步长跳过探测次数的平方的步数,即 1、4、9 步。
多次哈希
多次哈希使用多个哈希函数 f1(X)、f2(X)、f3(X)、... ,进行探测。
- 插入元素:若哈希函数 f1(X) 出现冲突,则尝试 f2(X),以此类推,直到找到空桶后插入元素。
- 查找元素:在相同的哈希函数顺序下进行查找,直到找到目标元素时返回;或当遇到空桶或已尝试所有哈希函数,说明哈希表中不存在该元素,则返回
null。
# 2.4、哈希算法
哈希算法就是计算哈希值,哈希值就是键值对在哈希表中的存储位置。
哈希算法的目标需要有如下特点(既快又稳)
- 确定性:对于相同的输入,哈希算法应始终产生相同的输出。这样才能确保哈希表是可靠的。
- 效率高:计算哈希值的过程应该足够快。计算开销越小,哈希表的实用性越高。
- 均匀分布:哈希算法应使得键值对平均分布在哈希表中。分布越平均,哈希冲突的概率就越低。
哈希算法设计
- 加法哈希:对输入的每个字符的 ASCII 码进行相加,将得到的总和作为哈希值。
- 乘法哈希:利用了乘法的不相关性,每轮乘以一个常数,将各个字符的 ASCII 码累积到哈希值中。
- 异或哈希:将输入数据的每个元素通过异或操作累积到一个哈希值中。
- 旋转哈希:将每个字符的 ASCII 码累积到一个哈希值中,每次累积之前都会对哈希值进行旋转操作。
常见哈希算法
- MD5 和 SHA-1 已多次被成功攻击,因此它们被各类安全应用弃用。
- SHA-2 系列中的 SHA-256 是最安全的哈希算法之一,仍未出现成功的攻击案例,因此常被用在各类安全应用与协议中。
- SHA-3 相较 SHA-2 的实现开销更低、计算效率更高,但目前使用覆盖度不如 SHA-2 系列。
# 3、AVL树
红黑树和AVL树都是平衡二叉树,而HashMap在Java8开始引入了红黑树,HashMap底层实现为数组+(链表或红黑树),所以这里先对这红黑树和AVL树有个大致的了解。
AVL树是严格的平衡二叉树,红黑树是一种弱平衡二叉树。
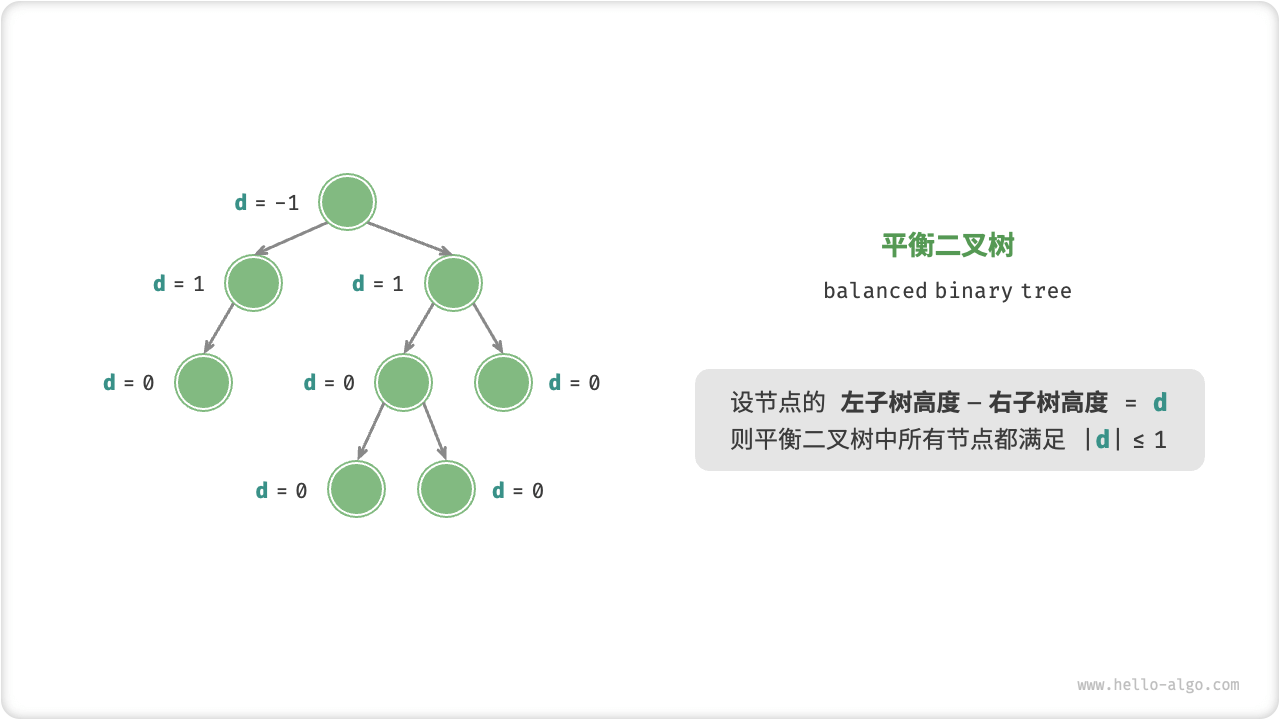
# 3.1、平衡二叉树
平衡二叉树:任意节点的左子树和右子树的高度之差的绝对值不超过 1 。
平衡二叉树结构
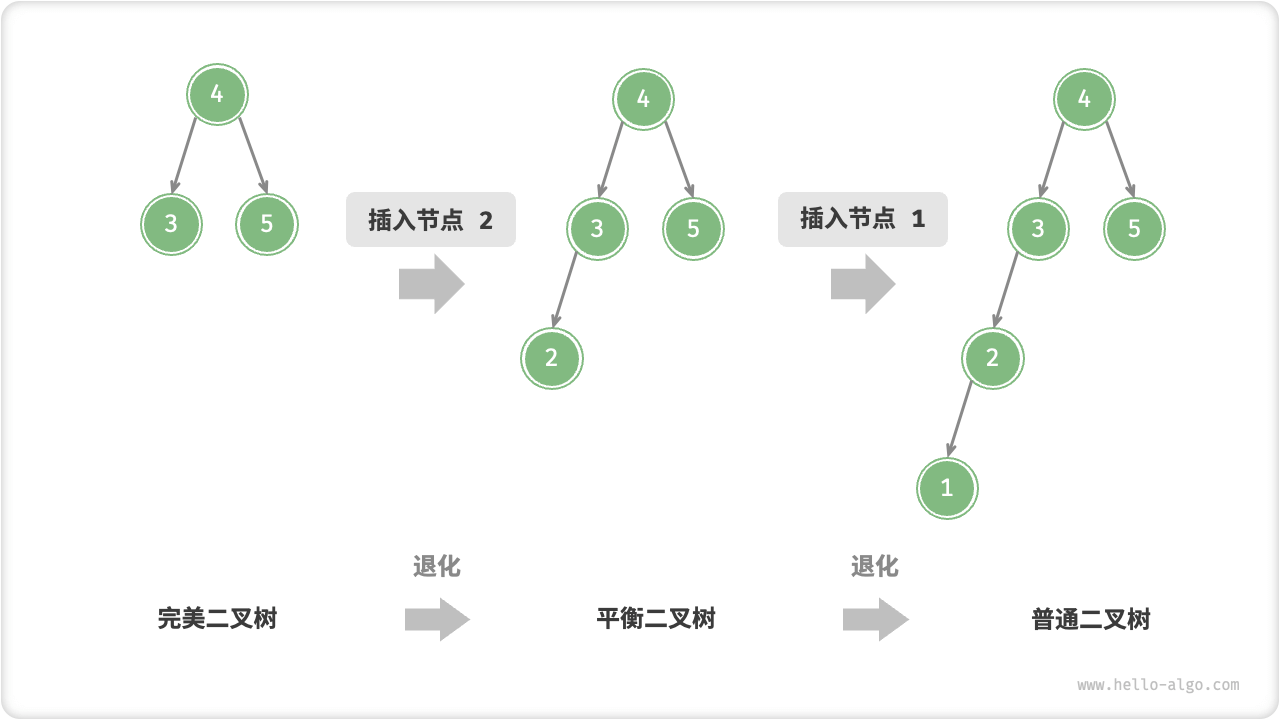
二叉树在多次插入和删除操作后,二叉搜索树可能退化为链表。所有操作的时间复杂度将从O(log n)恶化为O(n)。
二叉搜索树退化为链表过程

完美二叉树中插入两个节点后,树将严重向左倾斜,查找操作的时间复杂度也随之恶化。
当平衡二叉树退化为链表和普通二叉树时,对于所有操作的时间都会多,因此当平衡二叉树失去平衡时,需要进行旋转操作,使得树重新平衡。而红黑树和AVL树就是可以通过旋转使失去平衡 的二叉树重新平衡。也就是说红黑树和AVL树都是为了解决平衡二叉树退化为链表和普通二叉树的问题的解决方案。
红黑树和AVL树都是为了解决平衡二叉树退化为链表和普通二叉树的问题的解决方案。
# 3.2、AVL树
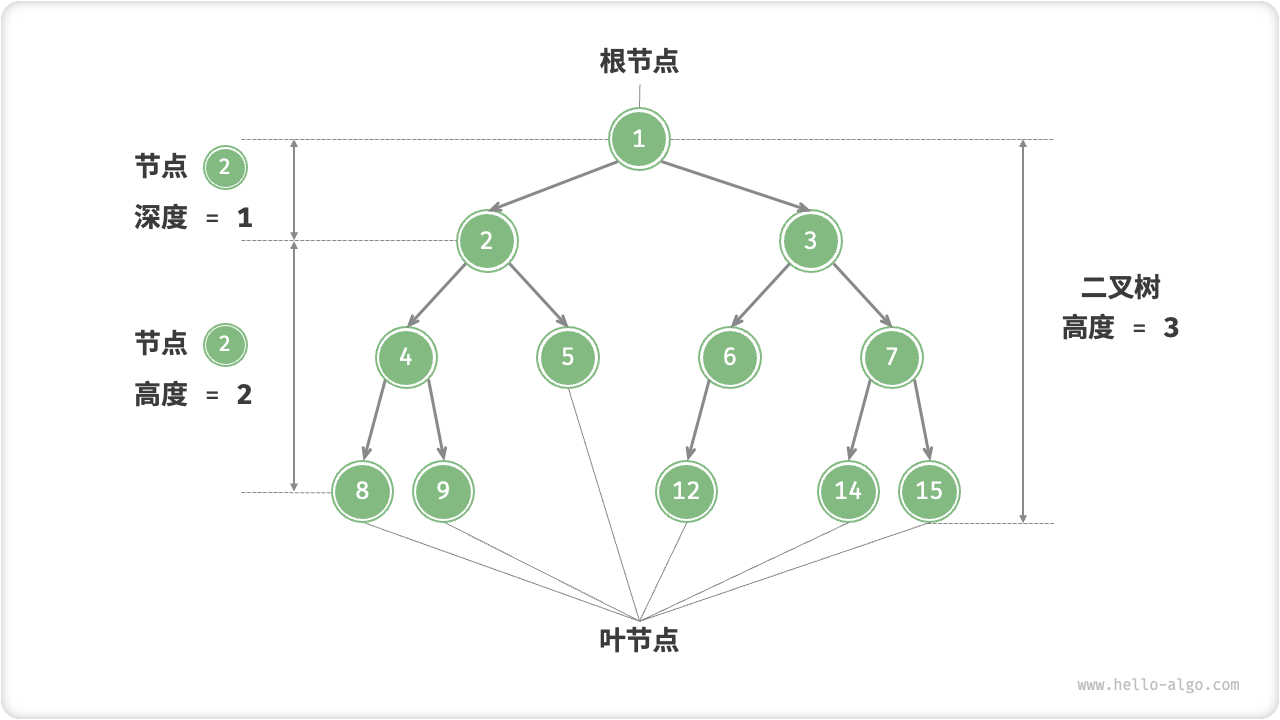
AVL树既是二叉搜索树也是平衡二叉树,同时满足这两类二叉树的所有性质,因此也被称为平衡二叉搜索树。
- 节点高度:是指从该节点到其最远叶节点的距离,即所经过的边的数量。需要特别注意的是,叶节点的高度为 0 ,而空节点的高度为 -1 。
- 节点平衡因子:为节点左子树的高度减去右子树的高度,同时规定空节点的平衡因子为 0 。
树的基本概念
# 3.3、AVL树旋转
AVL 树的特点在于旋转操作,它能够在不影响二叉树的中序遍历序列的前提下,使失衡节点重新恢复平衡。换句话说,旋转操作既能保持二叉搜索树的性质,也能使树重新变为平衡二叉树。
我们将平衡因子绝对值>1的节点称为失衡节点。根据节点失衡情况的不同,旋转操作分为四种:右旋、左旋、先右旋后左旋、先左旋后右旋。
# 3.4、AVL树右旋
案例1
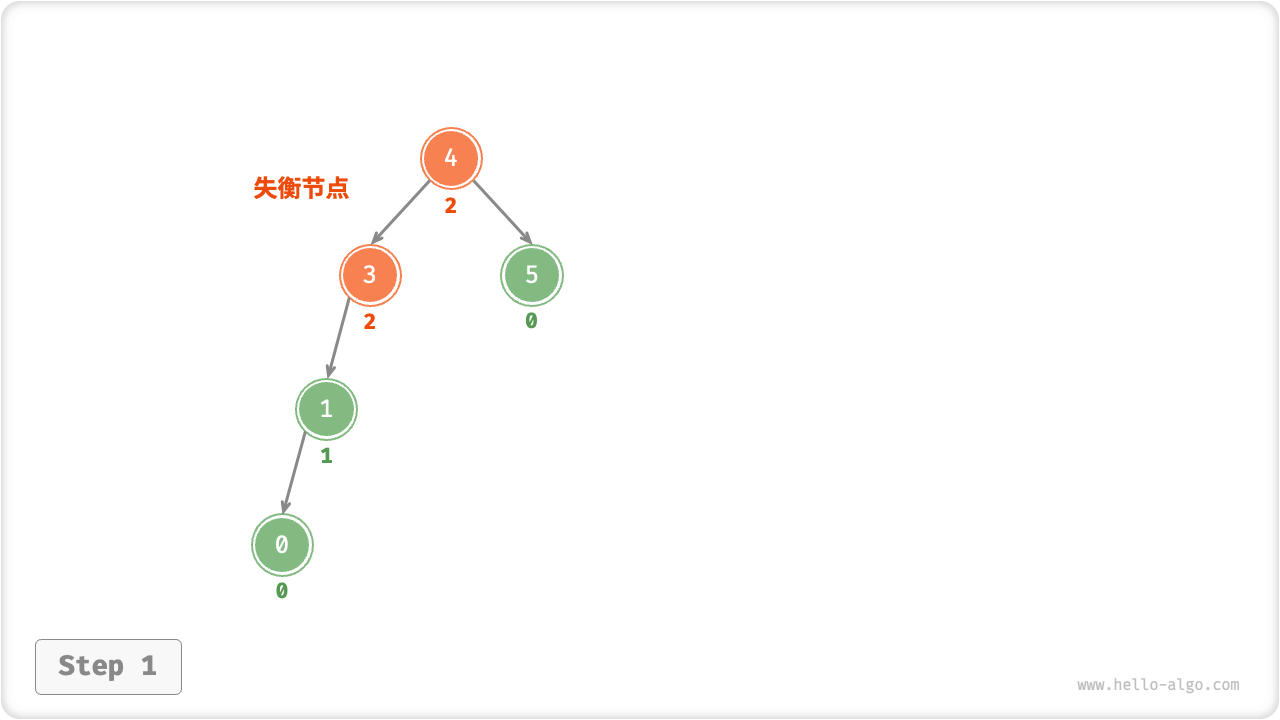


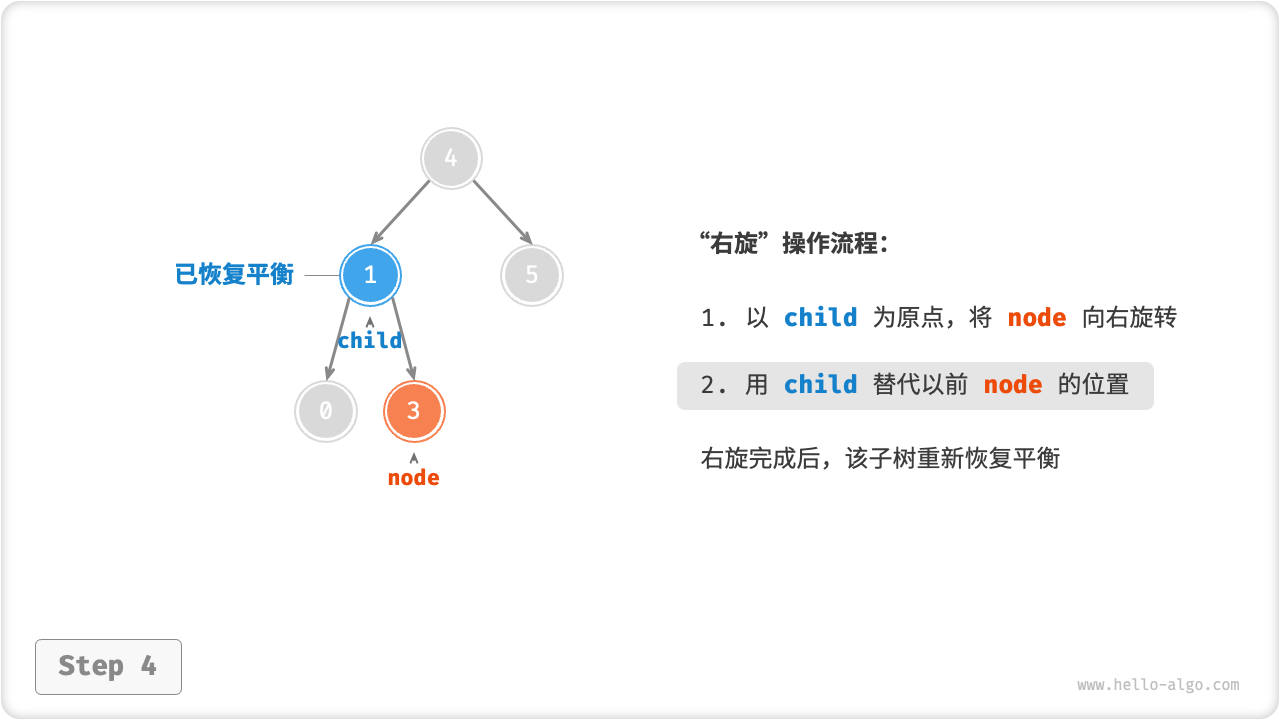
从底至顶看,二叉树中首个失衡节点是节点 3。我们关注以该失衡节点为根节点的子树,将该节点记为 node ,其左子节点记为 child ,执行右旋操作。完成右旋后,子树已经恢复平衡,并且仍然保持二叉搜索树的特性。
案例2
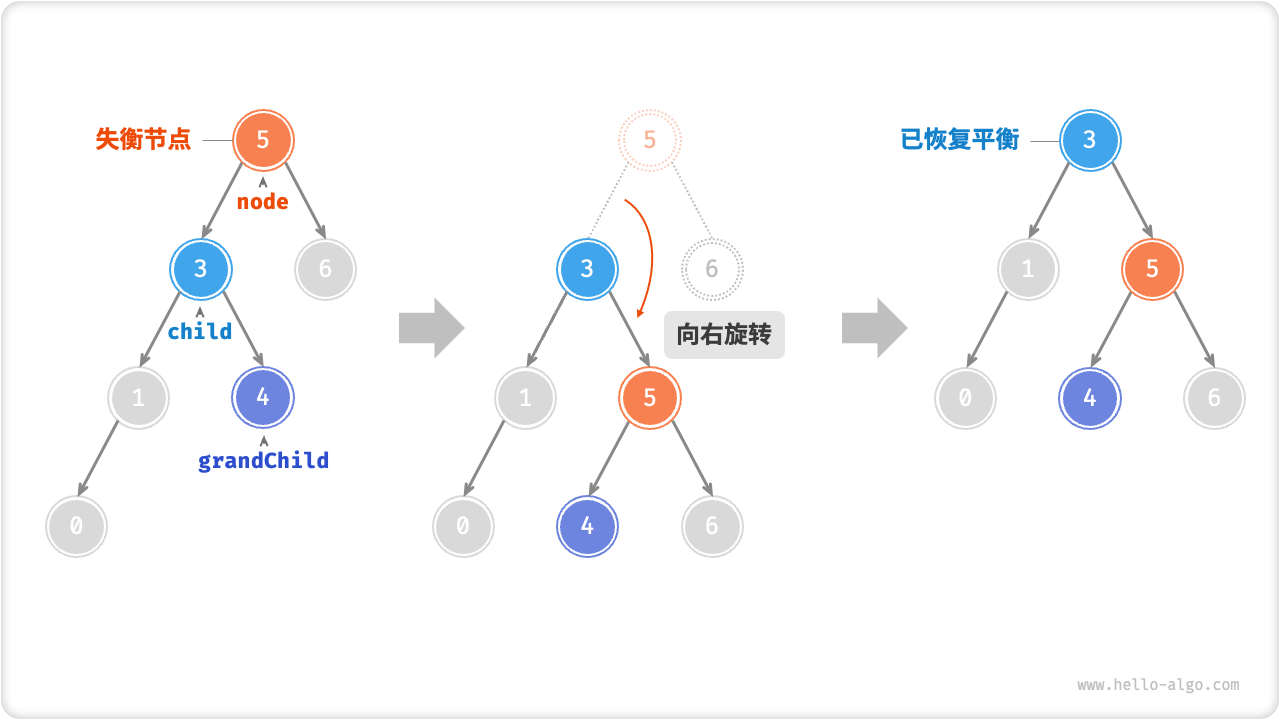
当节点 child 有右子节点(记为 grandChild )时,需要在右旋中添加一步:将 grandChild 作为 node 的左子节点。
# 3.5、AVL树左旋
右旋和左旋操作在逻辑上是镜像对称的,它们分别解决的两种失衡情况也是对称的。
案例1
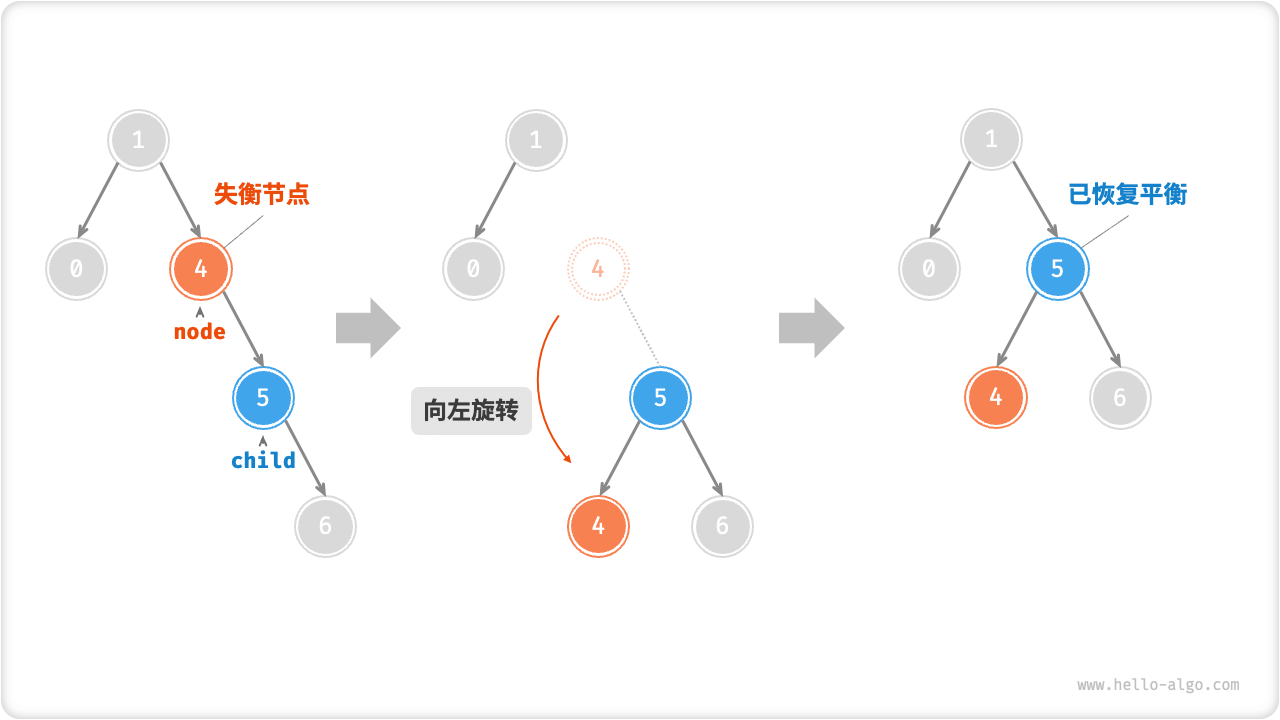
案例2
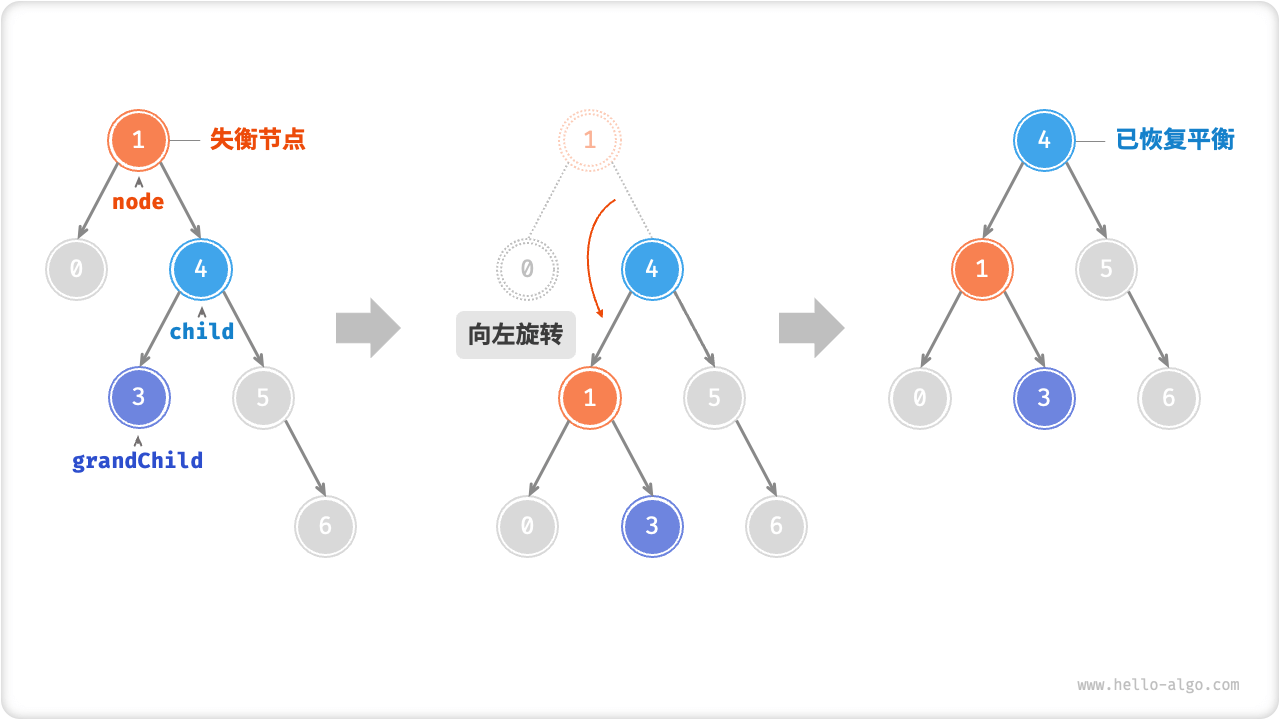
当节点 child 有左子节点(记为 grandChild )时,需要在左旋中添加一步:将 grandChild 作为 node 的右子节点。
# 3.6、AVL树先左旋后右旋
失衡节点 3 ,仅使用左旋或右旋都无法使子树恢复平衡。此时需要先对 child 执行左旋,再对 node 执行右旋。
先左旋后右旋

# 3.7、AVL树先右旋后左旋
对于上述失衡二叉树的镜像情况,需要先对 child 执行右旋,然后对 node 执行左旋。
先右旋后左旋

# 3.8、AVL树旋转的选择
四种失衡情况与上述案例逐个对应,分别需要采用右旋、左旋、先右后左、先左后右的旋转操作。
旋转的选择
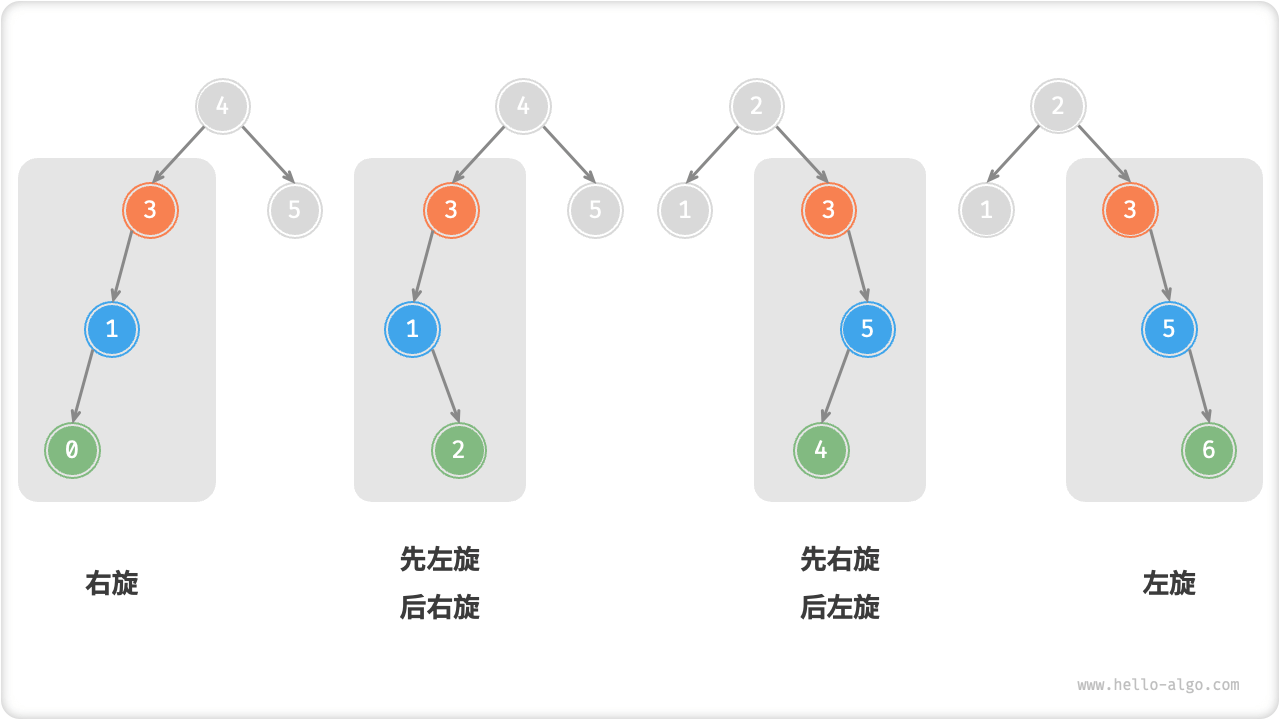
通过判断失衡节点的平衡因子以及较高一侧子节点的平衡因子的正负号,来确定失衡节点属于哪种情况旋转。
| 失衡节点的平衡因子 | 子节点的平衡因子 | 应采用的旋转方法 |
|---|---|---|
>1 (即左偏树) | >=0 | 右旋 |
>1 (即左偏树) | <0 | 先左旋后右旋 |
<-1(即右偏树) | <=0 | 左旋 |
<-1(即右偏树) | >0 | 先右旋后左旋 |
# 4、红黑树
# 4.1、红黑树概念
红黑树是一种自平衡二叉查找树,它与AVL树类似,都在添加和删除的时候通过旋转操作保持二叉树的平衡,以求更高效的查询性能。 与AVL树相比,红黑树牺牲了部分平衡性,以换取插入/删除操作时较少的旋转操作,整体来说性能要优于AVL树。
红黑树结构图
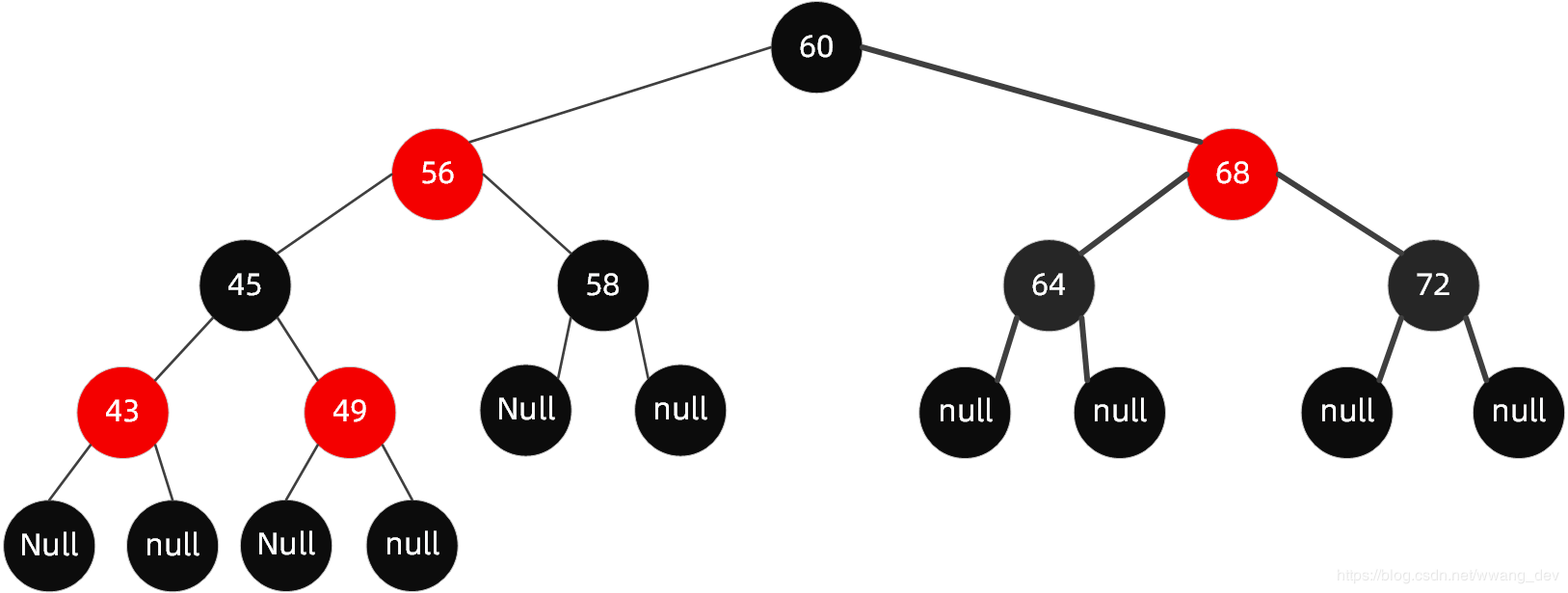
红黑树的规则特性
- 规则1:节点分为红色或者黑色。
- 规则2:根节点必为黑色。
- 规则3:叶子节点都为黑色,且为null。
- 规则4:连接红色节点的两个子节点都为黑色(红黑树不会出现相邻的红色节点)。
- 规则5:从任意节点出发,到其每个叶子节点的路径中包含相同数量的黑色节点。
- 推断特性规则:新加入到红黑树的节点为红色节点。
推断特性:新加入到红黑树的节点为红色节点。
从规则4中知道,当前红黑树中从根节点到每个叶子节点的黑色节点数量是一样的,此时假如新插入的是黑色节点的话,必然破坏规则(它所在的路径上会多出一个黑色节点),但加入红色节点却不一定,除非其父节点就是红色节点才会破坏规则,因此加入红色节点,破坏规则的可能性小一些。
# 4.2、红黑树平衡操作
当红黑树5个原则有一个不满足的情况,我们视为平衡被打破,就需要通过平衡操作重新恢复平衡。
平衡操作有三种:变色、左旋、右旋。
- 变色
节点的颜色由红变黑或由黑变红。
案例:
当该红黑树插入了51的时候,插入的节点为红色,父节点49也是红色,不符合规则4,这个时候就需要通过变色来恢复平衡。可能会需要多次变色才能恢复平衡。

步骤
- 将
49节点变为黑色。不符合规则5,需要接着变色。 - 将
45节点变为红色。不符合规则4,需要接着变色。 - 将
43和56节点变为黑色。符合所有规则,恢复平衡。
红黑树变色过程 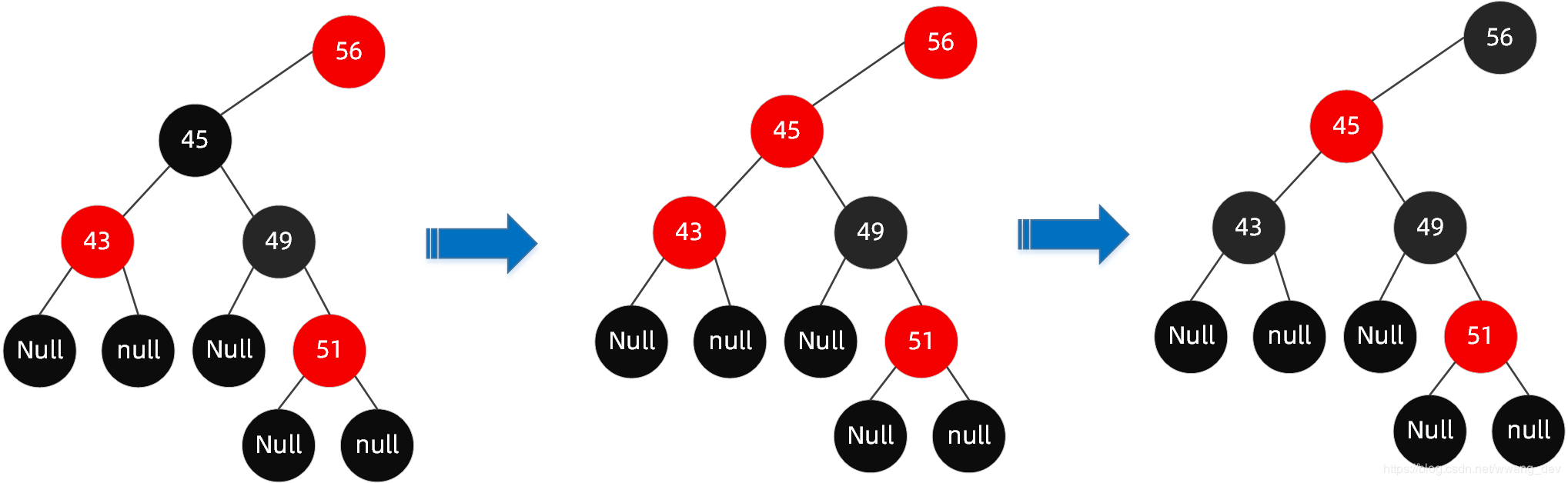
最终恢复平衡 
- 左旋
以某个结点作为支点(pivot),其父节点(子树的root)旋转为自己的左子树(左旋),pivot的原左子树变成 原root节点的 右子树,pivot的原右子树保持不变。
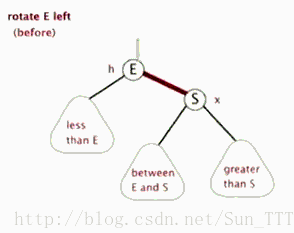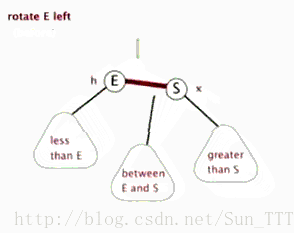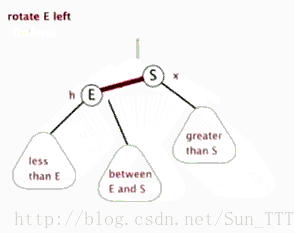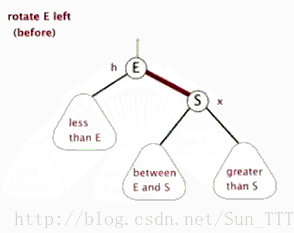
红黑树左旋 
- 右旋
以某个结点作为支点(pivot),其父节点(子树的root)旋转为自己的右子树(右旋),pivot的原右子树变成 原root节点的 左子树,pivot的原左子树保持不变。

红黑树右旋 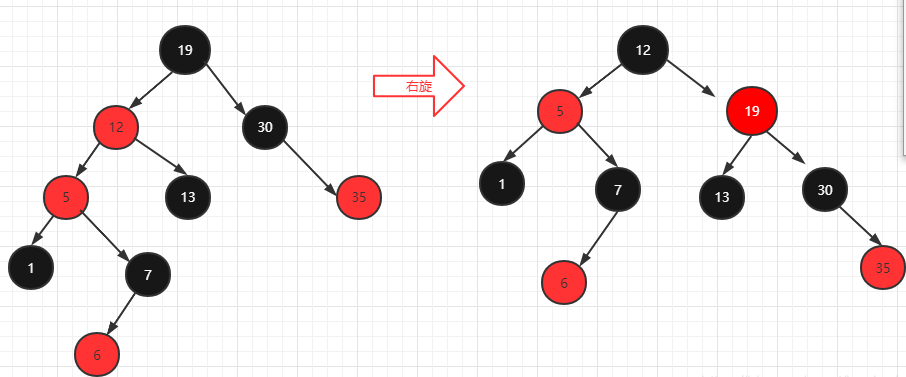
# 4.3、红黑树失衡情况
红黑树失衡的情况只有在执行插入和删除操作后,以下是红黑树需要进行平衡的情况:
- 插入操作失衡情况:
- 新插入的节点是根节点:将根节点涂为黑色以满足红黑树规则。
- 新插入的节点的父节点是红色:
- 红色父节点和红色叔节点都存在:通过重新上色操作来修正这种情况。
- 红色父节点和红色叔节点之一不存在或为黑色节点:进行旋转和重新上色操作来修正这种情况。
- 删除操作失衡情况:
- 删除的节点是红色:由于红色节点的删除不会破坏红黑树的规则,所以不需要进行平衡操作。
- 删除的节点是黑色:
- 删除的节点有一个红色子节点:将该子节点涂为黑色,不会破坏红黑树规则。
- 删除的节点没有子节点:进行旋转和重新上色操作来修正叶子节点的删除。
- 删除的节点有一个黑色子节点:需要根据子节点的兄弟节点和侄子节点的情况进行旋转和重新上色操作。
# 4.4、恢复平衡情况
- 当前节点(红色)的父节点是红色且当前节点的叔叔节点也是红色
- 把父节点设置为黑色
- 把叔叔节点也设置为黑色
- 把爷爷节点设置为红色
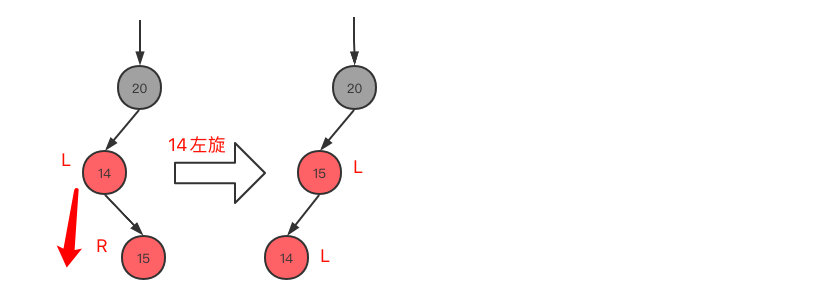
- 当前节点的父节点是红色,叔叔节点不存在或叔叔节点为黑色,且父节点是爷爷节点的左子节点
LL(/)型,也就是当前节点与父节点都处于左子节点
- 第一步,变色,父节点变为黑色,爷爷节点变为红色
- 第二步,右旋(由/型变为^型)
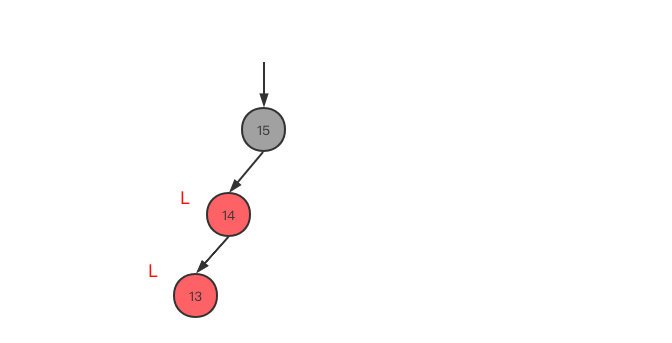
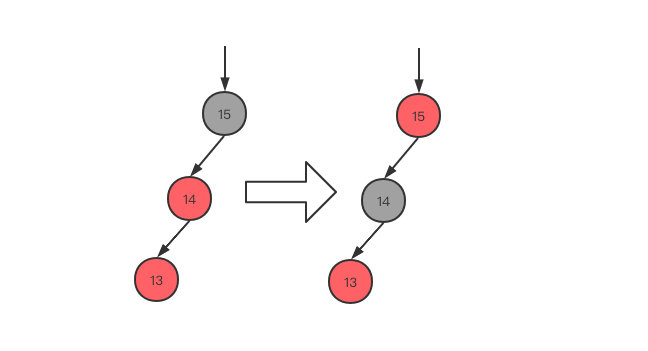

LR(<型),当前节点为父节点的右子树,父节点为爷爷节点的左子树
- 先变为LL,父节点14左旋
- 根据LL的规则,变色,旋转

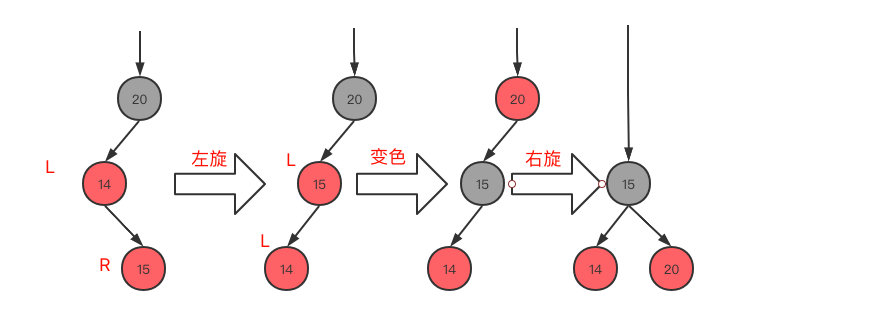
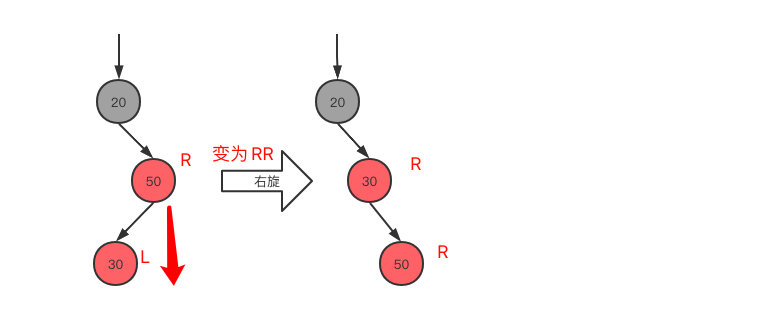
- 当前节点的父节点是红色,叔叔节点不存在或叔叔节点为黑色,且父节点是爷爷节点的右子节点
RR(\)型,也就是当前节点与父节点都处于右子节点
- 变颜色,父节点变为黑色,爷爷节点变为红色
- 爷爷节点为当前节点,左旋


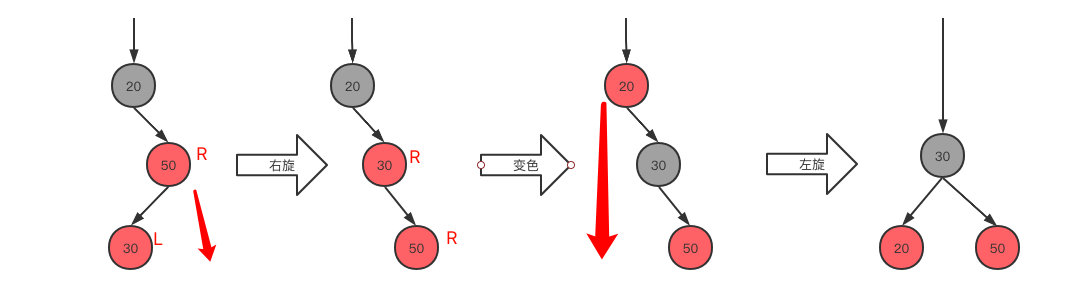
RL(>)型,当前节点在父节点的左子树,父节点在爷爷节点的右子树
- 先变为RR,右旋
- 根据RR,变色,左旋

# 5、HashMap源码解析
这里只做Java8的源码解析,想要了解Java7的可以自行去看看。我们在前面已经知道了HashMap的结构大致如下所示:
HashMap数据结构图
这里的结构是概念上的,实际上这么多元素时,早就已经扩容了。
# 5.1、参数解析
源码
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set<Map.Entry<K,V>> entrySet;
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
// ....
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
参数解析说明
| 参数 | 说明 |
|---|---|
DEFAULT_INITIAL_CAPACITY | HashMap的默认初始容量为16(即数组大小为16),这个值必须是2的幂。 |
MAXIMUM_CAPACITY | 如果HashMap初始化时指定了比这个值大的值,那么MAXIMUM_CAPACITY将被用作初始大小。这个最大容量为1 << 30,即1073741824,必须是2的幂并且小于等于1<<30。 |
DEFAULT_LOAD_FACTOR | 默认的负载因子,取值为0.75。负载因子决定了HashTable的数据密度,负载因子越大说明空间的利用率越高,冲突的可能性越大;反之,负载因子越小,空间浪费越严重。 |
TREEIFY_THRESHOLD | 当某个桶中的元素个数大于等于这个值时,会将链表转化为红黑树,提高查询效率,值为8。 |
UNTREEIFY_THRESHOLD | 就是当resize操作进行时,某个桶中的元素个数小于这个值,会把红黑树转化为链表,值为6。 |
MIN_TREEIFY_CAPACITY | 如果桶中的bin数量大于这个阈值,才会将bin转换为树,否则,如果bin过多,HashMap会选择扩容。这个值至少应该是TREEIFY_THRESHOLD的四倍。 |
table | 存储元素的数组,初始时为空,第一次插入元素时初始化,容量都是2的幂。 |
entrySet | 存储Map.Entry对象的集合。Map.Entry就是一个包含键值对的接口。 |
size | HashMap中存储的键值对的数量。 |
modCount | 当HashMap的结构发生改变时(即增加或删除entry),该字段会增加,主要用于迭代器迭代过程中的快速失败机制(ConcurrentModificationException)。 |
threshold | 阈值,当实际大小(键值对的数量)超过阈值时,会进行扩容。扩容后新的阈值(threshold)为(新的容量*加载因子)。也就是数组的容量。 |
loadFactor | 负载因子用于测量HashMap的满度,当实际大小(键值对数量)size超过(容量capacity*负载因子loadFactor)时,就需要将HashMap的容量翻倍。 |
Java8采用的是Node来存储节点数据,Node只能使用链表,红黑树的情况需要使用TreeNode。Java8之前采用的是Entry存储数据。
Node源码
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 5.1、hash()
hash()是HashMap的一种哈希算法,用于确认元素桶的下标位置。
源码
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 当key为null时,返回桶的位置是0,所以HashMap的首个桶的位置的元素一定是null。
- 当key不为null时,获取key的哈希值赋值给h,再和h的无符号右移16位做异或运算,得到key的桶的位置。
h ^ (h >>> 16)是将h的高16位和低16位异或,能够将h的高16位对h的低16位产生影响。使得哈希碰撞的机率更小。也就是确认桶的位置更分散。
# 5.1、构造函数
源码
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
/**
* Constructs a new <tt>HashMap</tt> with the same mappings as the
* specified <tt>Map</tt>. The <tt>HashMap</tt> is created with
* default load factor (0.75) and an initial capacity sufficient to
* hold the mappings in the specified <tt>Map</tt>.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
HashMap(int initialCapacity, float loadFactor)
这个构造方法可以初始化HashMap的容量和装载因子。装载因子就比较简单了,只要非空大于0的浮点数就直接赋值给HashMap中的loadFactor。
而容量阈值(threshold)就需要通过tableSizeFor()方法进行计算。
tableSizeFor()源码
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
2
3
4
5
6
7
8
9
10
11
12
HashMap的数组容量(tableSize)总是2的n次方。起始为16,当数组的元素数量超过容量的75%时就会进行扩容,数组容量翻倍。
- 先把传进函数的数值减1,结果赋值给n。
- 然后,依次右移1、2、4、8、16位后各和原值做或运算。这个操作的目的是将原数的最高位1后面的所有位全部变为1。例如,原数是17(二进制是10001),经过这一系列操作后变为31(二进制是11111)。
- 最后,比较结果并返回。当n小于0时返回1(这就是为什么HashMap的最小容量是1<<4=16,如果传入的值<=0,返回的就是这个值),当n大于等于最大容量MAXIMUM_CAPACITY(默认是1<<30),直接返回最大容量,否则返回n加1。
这个算法的优点是,返回的数一定是2的n次方,这样可以保证HashMap的效率最优。因为在确定数组的 index 位置时,HashMap 使用 (n - 1) & hash 计算,如果 n 是 2的幂次方则计算的结果一定能均匀分布在 0 - n 之间。
HashMap(int initialCapacity)和HashMap()
HashMap(int initialCapacity)就是调用了第一个构造,装载因子为默认值。HashMap()只是设置了默认装载因子。
HashMap(Map<? extends K, ? extends V> m)
这个构造函数支持传入一个Map对象,然后调用putMapEntries()方法将元素循环放入table中。
源码
/**
* Implements Map.putAll and Map constructor.
*
* @param m the map
* @param evict false when initially constructing this map, else
* true (relayed to method afterNodeInsertion).
*/
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
- table为空时,需要调用
tableSizeFor()初始化数组容量。
- if (table == null):判断当前的hash表是否为空,如果为空,则进行预分配大小。
- float ft = ((float)s / loadFactor) + 1.0F;计算新的容量(预估容量),s是预期的元素数量,loadFactor是加载因子,默认值为0.75,所以ft实际上就是预期元素数量除以加载因子。为什么要除以加载因子呢?因为HashMap约定当元素数量超过载入因子与容量的乘积时,进行扩容,所以根据预期的元素数量计算出应该有的最少容量,还要再加上1.0F,以防止元素个数刚好达到阈值,ft还是整数,导致下一次元素添加时立即触发扩容。
- int t = ((ft < (float)MAXIMUM_CAPACITY) ? (int)ft : MAXIMUM_CAPACITY); 然后确保计算出的新容量不超过HashMap的最大容量,如果超过则设置为最大容量。
- if (t > threshold) threshold = tableSizeFor(t); 这是个判断语句,如果新的预分配大小大于当前的阈值,就把阈值设置为新的容量(不过这个新的容量会再被tableSizeFor方法处理,得到一个2的幂次方大小的数)。阈值指的是HashMap进行扩容操作的临界值,等于(容量*加载因子)。
- 如果非空并且数量大于容量,则调用
resize()方法扩容。(后面会详解这个方法) - 最后循环将元素通过
putVal()方法放入table中。(后面会详解这个方法)
# 5.1、put()
源码并解析
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* int hash:键的哈希值
* K key:键
* V value:值
* boolean onlyIfAbsent:如果为true,则只有在键不存在时才存储值
* boolean evict:如果为false,则在插入新键值对时不会执行扩容操作
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; // 定义一个数组,用于存储键值对的链表或红黑树
Node<K,V> p; // 定义一个节点变量
int n, i; // 定义数组长度和索引
// 如果HashMap的数组table为空,或者数组长度为0,则先执行扩容操作
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 根据键的哈希值和数组的长度计算出键在数组中的索引i,并将对应位置的节点赋给变量p
if ((p = tab[i = (n - 1) & hash]) == null) // (n-1) & hash 是为了将结果限制在数组长度范围内。
// 如果节点为空,则直接创建一个新节点,并存入键和值
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 如果节点的哈希值和键与要存储的键值对的哈希值和键相等,则将节点赋给变量e
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果节点是树节点,则调用putTreeVal方法进行处理
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 循环遍历链表,直到到达链表末尾
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 创建一个新节点并存入键和值
p.next = newNode(hash, key, value, null);
// 当链表节点数量达到8时,将链表转化为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for the first
treeifyBin(tab, hash);
break;
}
// 如果节点的哈希值和键与要存储的键值对的哈希值和键相等,则将节点赋给变量e
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 如果e不为空,表示已存在相同的键,更新键对应的值
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
// 修改HashMap的修改次数
++modCount;
// 如果存储的键值对数量超过了阈值,则进行扩容操作
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
- putVal方法在HashMap中是插入一个键值对的核心方法,用于将键值对存入HashMap中。
- 首先判断是否需要进行数组的扩容,如果需要则调用resize方法进行扩容。
- 根据键的哈希值和数组的长度计算键在数组中的索引i,并获取对应位置的节点。
- 如果节点为空,则直接创建一个新节点,并存入键和值。
- 如果节点不为空,则使用循环遍历链表或红黑树,直到找到键值与要存储的键值对相等的节点或到达链表末尾。
- 如果找到了相同的键,更新键对应的值,并返回旧值。
- 如果没有找到相同的键,创建一个新节点,并添加到链表或红黑树中。
- 如果存储的键值对数量超过了阈值,进行扩容操作。
- 最后,执行插入后的操作(如快速失败检查和访问顺序调整)。
# 5.2、数组扩容()
resize()方法进行扩容
源码并解析
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; // 获取旧的数组
int oldCap = (oldTab == null) ? 0 : oldTab.length; // 计算旧数组的长度
int oldThr = threshold; // 获取旧的负载因子阈值
int newCap, newThr = 0; // 初始化新的容量和阈值为0
if (oldCap > 0) { // 如果旧数组不为空
if (oldCap >= MAXIMUM_CAPACITY) { // 如果旧容量大于等于最大容量
threshold = Integer.MAX_VALUE; // 阈值设为最大
return oldTab; // 返回旧数组
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) {
newThr = oldThr << 1; // 双倍容量的同时,将阈值也设置为双倍
}
}
else if (oldThr > 0) { // 如果旧容量为0但阈值大于0(表示初始容量被放在了阈值中)
newCap = oldThr; // 新容量设为旧阈值
}
else { // 如果旧容量和阈值都为0(表示使用默认值)
newCap = DEFAULT_INITIAL_CAPACITY; // 使用默认初始容量
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); // 根据默认负载因子计算出新的阈值
}
if (newThr == 0) { // 如果新的阈值为0
float ft = (float)newCap * loadFactor; // 计算新容量乘以负载因子
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); // 如果新容量小于最大容量且乘积小于最大容量,将乘积作为新的阈值,否则设为最大值
}
threshold = newThr; // 更新阈值
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; // 创建新的数组
table = newTab; // 将table引用指向新的数组
if (oldTab != null) { // 如果旧数组不为空
for (int j = 0; j < oldCap; ++j) { // 遍历旧数组
Node<K,V> e;
if ((e = oldTab[j]) != null) { // 如果旧数组某个位置有节点
oldTab[j] = null; // 将旧数组该位置设为null
if (e.next == null) {
newTab[e.hash & (newCap - 1)] = e; // 如果节点没有后继节点,直接放入新数组对应位置
}
else if (e instanceof TreeNode) {
((TreeNode<K,V>)e).split(this, newTab, j, oldCap); // 如果节点是红黑树节点,进行分割操作
}
else { // 如果是普通节点
Node<K,V> loHead = null, loTail = null; // 保存低位链表的头和尾节点
Node<K,V> hiHead = null, hiTail = null; // 保存高位链表的头和尾节点
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) { // 如果节点的hash值与旧容量进行与操作结果为0,放入低位链表
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else { // 否则放入高位链表
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) { // 将低位链表放入新数组对应位置
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) { // 将高位链表放入新数组对应位置
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab; // 返回新数组
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
这段代码主要是根据旧数组的容量和阈值,计算出新数组的容量和阈值,然后创建新数组,并根据旧数组中的节点重新组织节点的位置,最后返回新的数组。这个过程实现了HashMap的扩容功能。
# 5.3、get()
源码解析
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
* <p>A return value of {@code null} does not <i>necessarily</i>
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*
* @see #put(Object, Object)
*/
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods.
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
// 定义了四个变量:一个Node数组tab, 两个node节点first和e, 一个整型变量n和对象k.
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 && // 检查是否已经初始化了table,并且table的长度大于0
(first = tab[(n - 1) & hash]) != null) { // 根据hash值找到在table中的对应节点位置
if (first.hash == hash && // 总是检查链表的第一个节点,如果满足条件返回该节点
((k = first.key) == key || (key != null && key.equals(k)))) // 判断key是否和first节点的key相等
return first;
if ((e = first.next) != null) { // 如果第一个节点不满足条件,那么遍历之后的所有的节点
if (first instanceof TreeNode) // 如果节点类型是TreeNode,调用getTreeNode方法寻找
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash && // 判断key是否匹配
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null); // 持续遍历,如果链表中没有找到对应的key值,返回null
}
}
return null; // 如果还没有初始化table,那么直接返回null.
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# 6、HashSet
HashSet是对HashMap的简单包装,对HashSet的函数调用都会转换成合适的HashMap方法。只有不到300行代码。
特性
- 元素不允许重复。
- 存取速度快,主要通过hashCode()方法进行数据存取,所以对于快速查找大数据量信息很有优势。
- 不保证元素的顺序恒久不变。
源码
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
/**
* Constructs a new set containing the elements in the specified
* collection. The <tt>HashMap</tt> is created with default load factor
* (0.75) and an initial capacity sufficient to contain the elements in
* the specified collection.
*
* @param c the collection whose elements are to be placed into this set
* @throws NullPointerException if the specified collection is null
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* the specified initial capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* the specified initial capacity and default load factor (0.75).
*
* @param initialCapacity the initial capacity of the hash table
* @throws IllegalArgumentException if the initial capacity is less
* than zero
*/
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
/**
* Constructs a new, empty linked hash set. (This package private
* constructor is only used by LinkedHashSet.) The backing
* HashMap instance is a LinkedHashMap with the specified initial
* capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @param dummy ignored (distinguishes this
* constructor from other int, float constructor.)
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
/**
* Returns an iterator over the elements in this set. The elements
* are returned in no particular order.
*
* @return an Iterator over the elements in this set
* @see ConcurrentModificationException
*/
public Iterator<E> iterator() {
return map.keySet().iterator();
}
/**
* Returns the number of elements in this set (its cardinality).
*
* @return the number of elements in this set (its cardinality)
*/
public int size() {
return map.size();
}
/**
* Returns <tt>true</tt> if this set contains no elements.
*
* @return <tt>true</tt> if this set contains no elements
*/
public boolean isEmpty() {
return map.isEmpty();
}
/**
* Returns <tt>true</tt> if this set contains the specified element.
* More formally, returns <tt>true</tt> if and only if this set
* contains an element <tt>e</tt> such that
* <tt>(o==null ? e==null : o.equals(e))</tt>.
*
* @param o element whose presence in this set is to be tested
* @return <tt>true</tt> if this set contains the specified element
*/
public boolean contains(Object o) {
return map.containsKey(o);
}
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element <tt>e</tt> to this set if
* this set contains no element <tt>e2</tt> such that
* <tt>(e==null ? e2==null : e.equals(e2))</tt>.
* If this set already contains the element, the call leaves the set
* unchanged and returns <tt>false</tt>.
*
* @param e element to be added to this set
* @return <tt>true</tt> if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
/**
* Removes the specified element from this set if it is present.
* More formally, removes an element <tt>e</tt> such that
* <tt>(o==null ? e==null : o.equals(e))</tt>,
* if this set contains such an element. Returns <tt>true</tt> if
* this set contained the element (or equivalently, if this set
* changed as a result of the call). (This set will not contain the
* element once the call returns.)
*
* @param o object to be removed from this set, if present
* @return <tt>true</tt> if the set contained the specified element
*/
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
/**
* Removes all of the elements from this set.
* The set will be empty after this call returns.
*/
public void clear() {
map.clear();
}
/**
* Returns a shallow copy of this <tt>HashSet</tt> instance: the elements
* themselves are not cloned.
*
* @return a shallow copy of this set
*/
@SuppressWarnings("unchecked")
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
/**
* Save the state of this <tt>HashSet</tt> instance to a stream (that is,
* serialize it).
*
* @serialData The capacity of the backing <tt>HashMap</tt> instance
* (int), and its load factor (float) are emitted, followed by
* the size of the set (the number of elements it contains)
* (int), followed by all of its elements (each an Object) in
* no particular order.
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out HashMap capacity and load factor
s.writeInt(map.capacity());
s.writeFloat(map.loadFactor());
// Write out size
s.writeInt(map.size());
// Write out all elements in the proper order.
for (E e : map.keySet())
s.writeObject(e);
}
/**
* Reconstitute the <tt>HashSet</tt> instance from a stream (that is,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Consume and ignore stream fields (currently zero).
s.readFields();
// Read capacity and verify non-negative.
int capacity = s.readInt();
if (capacity < 0) {
throw new InvalidObjectException("Illegal capacity: " +
capacity);
}
// Read load factor and verify positive and non NaN.
float loadFactor = s.readFloat();
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new InvalidObjectException("Illegal load factor: " +
loadFactor);
}
// Clamp load factor to range of 0.25...4.0.
loadFactor = Math.min(Math.max(0.25f, loadFactor), 4.0f);
// Read size and verify non-negative.
int size = s.readInt();
if (size < 0) {
throw new InvalidObjectException("Illegal size: " + size);
}
// Set the capacity according to the size and load factor ensuring that
// the HashMap is at least 25% full but clamping to maximum capacity.
capacity = (int) Math.min(size * Math.min(1 / loadFactor, 4.0f),
HashMap.MAXIMUM_CAPACITY);
// Constructing the backing map will lazily create an array when the first element is
// added, so check it before construction. Call HashMap.tableSizeFor to compute the
// actual allocation size. Check Map.Entry[].class since it's the nearest public type to
// what is actually created.
SharedSecrets.getJavaOISAccess()
.checkArray(s, Map.Entry[].class, HashMap.tableSizeFor(capacity));
// Create backing HashMap
map = (((HashSet<?>)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor));
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
@SuppressWarnings("unchecked")
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
/**
* Creates a <em><a href="Spliterator.html#binding">late-binding</a></em>
* and <em>fail-fast</em> {@link Spliterator} over the elements in this
* set.
*
* <p>The {@code Spliterator} reports {@link Spliterator#SIZED} and
* {@link Spliterator#DISTINCT}. Overriding implementations should document
* the reporting of additional characteristic values.
*
* @return a {@code Spliterator} over the elements in this set
* @since 1.8
*/
public Spliterator<E> spliterator() {
return new HashMap.KeySpliterator<E,Object>(map, 0, -1, 0, 0);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
# 7、HashTable
Hashtable是Java的一种数据结构,可以用来存储键值对(key-value pairs)。它实现了Map接口,其中的键是唯一的,而值可以重复。Hashtable是线程安全的,可以用于多线程环境下。
Hashtable的内部实现是一个数组,数组的每个元素是一个链表。当插入一个键值对时,首先根据键的hash code计算出数组中的位置,如果该位置为空,则直接将键值对插入;如果该位置已经存在键值对,则将新的键值对追加到链表的末尾。当获取一个键值对时,同样根据键的hash code计算出数组中的位置,然后在链表中查找对应的键值对。
- Hashtable的常用方法包括:
- put(key, value):插入一个键值对
- get(key):根据键获取值
- remove(key):根据键删除键值对
- containsKey(key):判断是否包含指定的键
- containsValue(value):判断是否包含指定的值
- size():获取元素的个数
Hashtable的优点是线程安全,适用于多线程环境下。缺点是性能相对较低,因为多线程环境下需要加锁保证线程安全。此外,Hashtable不允许存储空键和空值。
在Java 1.2之后,推荐使用HashMap代替Hashtable。HashMap是Hashtable的非线程安全的版本,性能也比Hashtable要好。
- Hashtable和HashMap的区别
- 线程安全性:Hashtable是线程安全的,它的方法都是同步的,可以在多线程环境下使用,但性能相对较低。而HashMap是非线程安全的,如果多个线程同时对一个HashMap进行操作,可能会导致数据不一致的问题。
- 键和值的null值:Hashtable不允许存储null键和null值,如果尝试存储null值,会抛出NullPointerException。而HashMap允许存储一个null键和多个null值。
- 继承关系:Hashtable是基于Dictionary类实现的,而HashMap是基于AbstractMap类实现的。
- 迭代顺序:Hashtable的迭代顺序是不确定的,而HashMap的迭代顺序是不确定的,且不保证顺序恒定不变。
- 初始容量和扩容机制:Hashtable默认的初始容量为11,负载因子为0.75。而HashMap的默认初始容量为16,负载因子为0.75。当元素数量达到容量与负载因子的乘积时,Hashtable会进行扩容操作,扩容为原容量的两倍加一;HashMap也会进行类似的扩容操作,但扩容为原容量的两倍。
- Hashtable开发中用的比较少了,可以作为了解。
- Hashtable和ConcurrentHashMap都是Java所提供的线程安全的哈希表实现。
- 在日常开发中,一般推荐使用ConcurrentHashMap,因为其提供了比Hashtable更优秀的并发性能和更好的扩展能力。