DQL【数据查询语言】
半塘 2023/8/29 数据库MySQL
# 1、基础查询
# 1.1、语法
SELECT * | {[DISTINCT] column | expression[alias], ...} FROM table;
1
特点
- 查询列表可以是:表中的字段、常量值、表达式、函数
- 查询的结果是一个虚拟的表格
例子:test库下有个employees(员工)表
# 切库
USE test;
# 1.查询表中的单个字段
SELECT last_name FROM employees;
# 2.查询表中的多个字段
SELECT last_name, salary, email FROM employees;
# 3.查询表中的所有字段,能查字段尽量别用 *
# 方式一:
SELECT
`employee_id`,
`first_name`,
`last_name`,
`phone_number`,
`last_name`,
`job_id`,
`phone_number`,
`job_id`,
`salary`,
`commission_pct`,
`manager_id`,
`department_id`,
`hiredate`
FROM
employees;
# 方式二:
SELECT * FROM employees;
# 4.查询常量值
SELECT 100;
SELECT 'john';
# 5.查询表达式
SELECT 100%98;
# 6.查询函数
SELECT VERSION();
# 7.起别名,如果要查询的字段有重名的情况,使用别名可以区分开来
# 方式一:使用as
SELECT 100%98 AS 结果;
SELECT last_name AS 姓,first_name AS 名 FROM employees;
# 方式二:使用空格
SELECT last_name 姓,first_name 名 FROM employees;
# 例如:查询salary,显示结果为 out put
SELECT salary AS "out put" FROM employees; #单引号也行
# 8.DISTINCT 去重
# 例如:查询员工表中涉及到的所有的部门编号
SELECT DISTINCT department_id FROM employees;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
# 1.2、+号的作用
只有一个功能:运算符
# 两个操作数都为数值型,则做加法运算
select 100+90;
# 只要其中一方为字符型,试图将字符型数值转换成数值型。如果转换成功,则继续做加法运算
select '123'+90;
# 如果转换失败,则将字符型数值转换成0
select 'john'+90;
# 只要其中一方为null,则结果肯定为null
select null+10;
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# 1.3、CONCAT、ISNULL、IFNULL
CONCAT:合并两个字符串
SELECT CONCAT('a','b','c') AS 结果;
# 结果为:abc
1
2
2
ISNULL:判断某字段或表达式是否为null,是返回1,否则返回0
SELECT ISNULL('a') AS 结果;
# 结果为:0
1
2
2
IFNULL:如果第一个参数的表达式 expression 为 null,则返回第二个参数的备用值,可嵌套使用
SELECT IFNULL(commission_pct, 0) AS 奖金率, commission_pct FROM employees;
1
# 2、条件查询
# 2.1、语法
select 查询列表 from 表名 where 筛选条件;
1
根据条件过滤原始表的数据,查询到想要的数据
# 2.2、分类
- 按条件表达式筛选
用于筛选数据
| 操作符 | 说明 |
|---|---|
| = | 等于 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| <> | 不等于,等价于!= |
- 按逻辑表达式筛选
用于连接条件表达式
| 操作符 | 说明 |
|---|---|
| and | 与,逻辑并 |
| or | 或,逻辑或 |
| not | 非,逻辑否 |
- 范围查询
不确定条件进行范围查询,或者模糊查询
| 操作符 | 说明 |
|---|---|
| between A and B | 在A和B直接,包含两边边界 |
| in | 等于列表中的一个 |
| like | 模糊查询,需要跟%一起用 |
| is null | 空值,仅仅可以判断NULL值,可读性较高,建议使用 |
| is not null | 非空值 |
| <=> | 安全等于,既可以判断NULL值,又可以判断普通的数值,可读性较低 |
例子练习
#一、按条件表达式筛选
/*
特点:
①一般和通配符搭配使用
通配符:
% 任意多个字符,包含0个字符
_ 任意单个字符
*/
#案例1:查询员工名中包含字符a的员工信息
select *
from employees
where last_name like '%a%'; #abc
#案例2:查询员工名中第三个字符为e,第五个字符为a的员工名和工资
select last_name, salary
FROM employees
WHERE last_name LIKE '__e_a%';
#案例3:查询员工名中第二个字符为_的员工名的
SELECT last_name
FROM employees
WHERE last_name LIKE '_$_%' ESCAPE '$'; #指定$为转移字符
#WHERE last_name LIKE '_\_%';
#2.between and
/*
①使用between and可以提高语句的简洁度
②包含临界值
③两个临界值不要调换顺序
*/
#案例:查询员工编号在100到120之间的员工信息
SELECT *
FROM employees
WHERE employee_id >= 100 AND employee_id <= 120;
#----------------------
SELECT *
FROM employees
WHERE employee_id BETWEEN 100 AND 120;
#3.in
/*
含义:判断某字段的值是否属于in列表中的某一项
特点:
①使用in提高语句简洁度
②in列表的值类型必须一致或兼容
③in列表中不支持通配符
*/
#案例:查询员工的工种编号是 IT_PROG、AD_VP、AD_PRES中的一个员工名和工种编号
SELECT last_name, job_id
FROM employees
WHERE job_id = 'IT_PROT'
OR job_id = 'AD_VP'
OR JOB_ID = 'AD_PRES';
#-----------------------
SELECT last_name, job_id
FROM employees
WHERE job_id IN ('IT_PROT', 'AD_VP', 'AD_PRES');
#4、is null
/*
=或<>不能用于判断null值
is null或is not null 可以判断null值
*/
#案例1:查询没有奖金的员工名和奖金率
SELECT last_name, commission_pct
FROM employees
WHERE commission_pct IS NULL;
#案例2:查询有奖金的员工名和奖金率
SELECT last_name, commission_pct
FROM employees
WHERE commission_pct IS NOT NULL;
#----------------以下为❌
SELECT last_name, commission_pct
FROM employees
WHERE salary IS 12000;
# 5、<=>
#案例1:查询没有奖金的员工名和奖金率
SELECT last_name, commission_pct
FROM employees
WHERE commission_pct <=> NULL;
#案例2:查询工资为12000的员工信息
SELECT last_name, salary
FROM employees
WHERE salary <=> 12000;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
# 3、排序查询
语法
select 要查询的东西 from 表 where 条件 order by 排序的字段|表达式|函数|别名 [asc | desc];
1
- asc代表的是升序,可以省略,desc代表的是降序
- order by子句可以支持单个字段、别名、表达式、函数、多个字段
- order by子句在查询语句的最后面,除了limit子句
例子练习
#1、按单个字段排序
SELECT * FROM employees ORDER BY salary DESC;
#2、添加筛选条件再排序
#案例:查询部门编号>=90的员工信息,并按员工编号降序
SELECT *
FROM employees
WHERE department_id>=90
ORDER BY employee_id DESC;
#3、按表达式排序
#案例:查询员工信息 按年薪降序
SELECT *, salary*12*(1+IFNULL(commission_pct,0))
FROM employees
ORDER BY salary*12*(1+IFNULL(commission_pct,0)) DESC;
#4、按别名排序
#案例:查询员工信息 按年薪升序
SELECT *, salary*12*(1+IFNULL(commission_pct,0)) 年薪
FROM employees
ORDER BY 年薪 ASC;
#5、按函数排序
#案例:查询员工名,并且按名字的长度降序
SELECT LENGTH(last_name), last_name
FROM employees
ORDER BY LENGTH(last_name) DESC;
#6、按多个字段排序
#案例:查询员工信息,要求先按工资降序,再按employee_id升序
SELECT *
FROM employees
ORDER BY salary DESC, employee_id ASC;
#7.查询员工的姓名和部门号和年薪,按年薪降序 按姓名升序
SELECT last_name, department_id, salary*12*(1+IFNULL(commission_pct,0)) 年薪
FROM employees
ORDER BY 年薪 DESC, last_name ASC;
#8.选择工资不在8000到17000的员工的姓名和工资,按工资降序
SELECT last_name, salary
FROM employees
WHERE salary NOT BETWEEN 8000 AND 17000
ORDER BY salary DESC;
#9.查询邮箱中包含e的员工信息,并先按邮箱的字节数降序,再按部门号升序
SELECT *, LENGTH(email)
FROM employees
WHERE email LIKE '%e%'
ORDER BY LENGTH(email) DESC, department_id ASC;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 4、内置函数
类似于java的方法,将一组逻辑语句封装在方法体中,对外暴露方法名
优点
- 隐藏了实现细节
- 提高代码的重用性
调用
select 函数名(实参列表) [from 表];
1
分类
单行函数
如 concat、length、ifnull等
分组函数
功能:做统计使用,又称为统计函数、聚合函数、组函数
# 4.1、单行函数
- 字符函数
| 函数 | 说明 |
|---|---|
| length() | 获取字节个数(utf-8一个汉字代表3个字节,gbk为2个字节) |
| concat() | 拼接 |
| substring() | 截取子串 |
| upper() | 转换成大写 |
| lower() | 转换成小写 |
| trim() | 去前后指定的空格或指定字符 |
| ltrim() | 去左边空格 |
| rtrim() | 去右边空格 |
| replace() | 全部替换 |
| lpad() | 左填充 |
| rpad() | 右填充 |
| instr() | 返回子串第一次出现的索引,找不到返回0 |
例子练习
#1.length 获取参数值的字节个数
SELECT LENGTH('john');
SELECT LENGTH('张三丰hahaha');
SHOW VARIABLES LIKE '%char%'
#2.concat 拼接字符串
SELECT CONCAT(last_name,'_',first_name) 姓名 FROM employees;
#3.upper、lower
SELECT UPPER('john');
SELECT LOWER('joHn');
#示例:将姓变大写,名变小写,然后拼接
SELECT CONCAT(UPPER(last_name),LOWER(first_name)) 姓名 FROM employees;
#4.substr/substring
注意:索引从1开始
#截取从指定索引处后面所有字符
SELECT SUBSTRING('李莫愁爱上了陆展元', 7) out_put; #陆展元
#截取从指定索引处指定字符长度的字符
SELECT SUBSTRING('李莫愁爱上了陆展元', 1, 3) out_put; #李莫愁
#案例:姓名中首字符大写,其他字符小写然后用_拼接,显示出来
SELECT CONCAT(UPPER(SUBSTR(last_name,1,1)),'_',LOWER(SUBSTR(last_name,2))) out_put
FROM employees;
#5.instr 返回子串第一次出现的索引,如果找不到返回0
SELECT INSTR('杨不悔爱上了殷六侠','殷六侠') AS out_put;
#6.trim
SELECT LENGTH(TRIM(' 张翠山 ')) AS out_put;
#不仅可以去空格,还能去指定字符
SELECT TRIM('aa' FROM 'aaaaaaaaa张aaa翠山aaaaaaaaaaaaaa') AS out_put;
#7.lpad 用指定的字符实现左填充指定长度
SELECT LPAD('殷素素',2,'*') AS out_put; #殷素
#8.rpad 用指定的字符实现右填充指定长度
SELECT RPAD('殷素素',12,'ab') AS out_put; #殷素素ababababa
#9.replace 全部替换替换
SELECT REPLACE('周芷若周芷若周芷若周芷若张无忌爱上了周芷若','周芷若','赵敏') AS out_put;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
- 数学函数
| 函数 | 说明 |
|---|---|
| round() | 四舍五入 |
| floor() | 向下取整 |
| ceil() | 向上取整 |
| mod() | 取余 |
| truncate() | 截断 |
| rand() | 产生0-1之间的一个随机数 |
例子练习
#round 四舍五入
SELECT ROUND(-1.55);
SELECT ROUND(1.567, 2); #1.57
#ceil 向上取整,返回>=该参数的最小整数
SELECT CEIL(-1.02);
#floor 向下取整,返回<=该参数的最大整数
SELECT FLOOR(-9.99);
#truncate 截断,第二个参数为保留几位小数
SELECT TRUNCATE(1.69999, 1);
#mod取余
/*
mod(a,b) : a-a/b*b
mod(-10,-3):-10- (-10)/(-3)*(-3)=-1
*/
SELECT MOD(10,-3);
SELECT 10%3;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 日期函数
| 函数 | 说明 |
|---|---|
| now() | 当前系统日期+时间 |
| curdate() | 当前系统日期 |
| curtime() | 当前系统时间 |
| str_to_date() | 将字符转换成日期 |
| date_format() | 将日期转换成字符 |
| year() | 获取年 |
| month() | 获取月 |
| monthname() | 获取月名称 |
| day() | 天 |
| hour() | 小时 |
| minute() | 分钟 |
| second() | 秒 |
| datediff() | 返回两个时间差了多少天 |
| datediff() | 两个时间相差的天数 |

例子练习
#now 返回当前系统日期+时间
SELECT NOW();
#curdate 返回当前系统日期,不包含时间
SELECT CURDATE();
#curtime 返回当前时间,不包含日期
SELECT CURTIME();
#可以获取指定的部分,年、月、日、小时、分钟、秒
SELECT YEAR(NOW()) 年;
SELECT YEAR('1998-1-1') 年;
SELECT YEAR(hiredate) 年 FROM employees;
SELECT MONTH(NOW()) 月;
SELECT MONTHNAME(NOW()) 月;
#str_to_date 将字符通过指定的格式转换成日期
SELECT STR_TO_DATE('1998-3-2','%Y-%c-%d') AS out_put;
#查询入职日期为1992-4-3的员工信息
SELECT * FROM employees WHERE hiredate = '1992-4-3';
SELECT * FROM employees WHERE hiredate = STR_TO_DATE('4-3 1992','%c-%d %Y');
#date_format 将日期转换成字符
SELECT DATE_FORMAT(NOW(),'%y年%m月%d日') AS out_put;
#查询有奖金的员工名和入职日期(xx月/xx日 xx年)
SELECT last_name, DATE_FORMAT(hiredate,'%m月/%d日 %y年') 入职日期
FROM employees
WHERE commission_pct IS NOT NULL;
# DATEDIFF() 两个时间相差的天数
SELECT DATEDIFF(MAX(hiredate), MIN(hiredate)) DIFFERENCE
from employees;
SELECT DATEDIFF("2019-7-7", "2016-7-7"); #1095
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
- 其他函数
| 函数 | 说明 |
|---|---|
| version() | 版本 |
| database() | 当前库 |
| user() | 当前连接用户 |
| password("用户名") | 返回字符的密码形式 |
| md5() | 同上 |
例子练习
SELECT VERSION();
SELECT DATABASE();
SELECT USER();
SELECT PASSWORD("root");
1
2
3
4
2
3
4
- 流程控制函数
都是处理分支情况
| 函数 | 说明 |
|---|---|
| if() | 处理等值判断 |
| case语句 | 处理条件判断 |
例子练习
#1.if函数: if else 的效果
SELECT IF(10<5,'大','小');
SELECT last_name,commission_pct,IF(commission_pct IS NULL,'没奖金,呵呵','有奖金,嘻嘻') 备注
FROM employees;
#2.case函数的使用一: switch case 的效果
/*
java中
switch(变量或表达式) {
case 常量1:语句1;break;
...
default:语句n;break;
}
mysql中
case 要判断的字段或表达式
when 常量1 then 要显示的值1或语句1; #语句时才用分号
when 常量2 then 要显示的值2或语句2;
...
else 要显示的值n或语句n;
end
*/
/*案例:查询员工的工资,要求
部门号=30,显示的工资为1.1倍
部门号=40,显示的工资为1.2倍
部门号=50,显示的工资为1.3倍
其他部门,显示的工资为原工资
*/
SELECT salary 原始工资, department_id,
CASE department_id
WHEN 30 THEN salary * 1.1
WHEN 40 THEN salary * 1.2
WHEN 50 THEN salary * 1.3
ELSE salary
END AS 新工资
FROM employees;
#3.case 函数的使用二:类似于 多重if
/*
java中:
if(条件1){
语句1;
}else if(条件2){
语句2;
}
...
else{
语句n;
}
mysql中:
case
when 条件1 then 要显示的值1或语句1
when 条件2 then 要显示的值2或语句2
...
else 要显示的值n或语句n
end
*/
#案例:查询员工的工资的情况
如果工资>20000,显示A级别
如果工资>15000,显示B级别
如果工资>10000,显示C级别
否则,显示D级别
SELECT salary,
CASE
WHEN salary > 20000 THEN 'A'
WHEN salary > 15000 THEN 'B'
WHEN salary > 10000 THEN 'C'
ELSE 'D'
END AS 工资级别
FROM employees;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
# 4.2、分组函数
- sum和avg一般用于处理数值型,max、min、count可以处理任何数据类型
- 以上五个分组函数都忽略null值,都可以搭配distinct使用,用于统计去重后的结果
- count的参数可以支持:字段、
*、常量值(一般放1),建议使用count(*) - 和分组函数一同查询的字段要求是group by后的字段
| 函数 | 说明 |
|---|---|
| sum() | 求和 |
| max() | 最大值 |
| min() | 最小值 |
| avg() | 平均值 |
| count() | 计数 |
例子练习
#1、简单 的使用
SELECT SUM(salary) FROM employees;
SELECT AVG(salary) FROM employees;
SELECT MIN(salary) FROM employees;
SELECT MAX(salary) FROM employees;
SELECT COUNT(salary) FROM employees;
SELECT SUM(salary) 和,AVG(salary) 平均,MAX(salary) 最高,MIN(salary) 最低,COUNT(salary) 个数
FROM employees;
SELECT SUM(salary) 和, ROUND(AVG(salary),2) 平均, COUNT(salary) 个数
FROM employees;
#2、参数支持哪些类型
SELECT SUM(last_name), AVG(last_name) FROM employees; #无意义
SELECT SUM(hiredate), AVG(hiredate) FROM employees; #无意义
SELECT MAX(last_name), MIN(last_name) FROM employees;
SELECT MAX(hiredate), MIN(hiredate) FROM employees;
SELECT COUNT(commission_pct) FROM employees;
SELECT COUNT(last_name) FROM employees;
#3、是否忽略null
SELECT SUM(commission_pct), AVG(commission_pct),
SUM(commission_pct)/35, SUM(commission_pct)/107
FROM employees;
SELECT MAX(commission_pct) ,MIN(commission_pct) FROM employees;
SELECT COUNT(commission_pct) FROM employees;
SELECT commission_pct FROM employees;
#4、和distinct搭配
SELECT SUM(DISTINCT salary), SUM(salary) FROM employees;
SELECT COUNT(DISTINCT salary), COUNT(salary) FROM employees;
#5、count函数的详细介绍
SELECT COUNT(salary) FROM employees;
SELECT COUNT(*) FROM employees;
SELECT COUNT(1) FROM employees; #相当于多了一列,值均为1
效率:
MYISAM存储引擎下,COUNT(*)的效率高
INNODB存储引擎下,COUNT(*)和COUNT(1)的效率差不多,比COUNT(字段)要高一些
#6、和分组函数一同查询的字段有限制
SELECT AVG(salary),employee_id FROM employees; #❌无意义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 5、分组查询
语法
select 分组函数 groupby后的字段 from 表
[where 筛选条件]
group by 分组的字段
[having 筛选条件]
[order by 排序的字段];
1
2
3
4
5
2
3
4
5
特点
- 和分组函数一同查询的字段最好是分组后的字段
- 分组查询筛选分为两类
- 分组函数做条件肯定放在having子句中
- 能用分组前筛选的,就优先考虑分组前筛选,性能考虑
- 支持单个字段分组,也支持多个字段分组,字段之间用逗号隔开,没有顺序要求,也支持函数和表达式
- 可以添加排序,放在分组查询的最后
- group by 和 having 后可以支持别名,但不要用,因为Oracle等不支持
例子练习
#1.简单的分组
#案例1:查询每个工种的员工平均工资
SELECT AVG(salary), job_id
FROM employees
GROUP BY job_id;
#案例2:查询每个位置的部门个数
SELECT COUNT(*), location_id
FROM departments
GROUP BY location_id;
#2、可以实现分组前的筛选
#案例1:查询邮箱中包含a字符的 每个部门的最高工资
SELECT MAX(salary), department_id
FROM employees
WHERE email LIKE '%a%'
GROUP BY department_id;
#案例2:查询有奖金的每个领导手下员工的平均工资
SELECT AVG(salary), manager_id
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY manager_id;
#3、分组后筛选
#案例:查询哪个部门的员工个数>5
#①查询每个部门的员工个数
SELECT COUNT(*), department_id
FROM employees
GROUP BY department_id;
#②筛选刚才①结果
SELECT COUNT(*), department_id
FROM employees
GROUP BY department_id
HAVING COUNT(*)>5;
#案例2:每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
SELECT job_id, MAX(salary)
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING MAX(salary) > 12000;
#案例3:领导编号>102的每个领导手下的最低工资大于5000的领导编号和最低工资
SELECT manager_id, MIN(salary)
FROM employees
WHERE manager_id > 102
GROUP BY manager_id
HAVING MIN(salary) > 5000;
#4.添加排序
#案例:每个工种有奖金的员工的最高工资>6000的工种编号和最高工资,按最高工资升序
SELECT job_id, MAX(salary) m
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING m>6000
ORDER BY m;
#5.按多个字段分组
#案例:查询每个工种每个部门的最低工资,并按最低工资降序
SELECT MIN(salary), job_id, department_id
FROM employees
GROUP BY department_id, job_id
ORDER BY MIN(salary) DESC;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
# 6、多表连接查询
# 6.1、含义及现象
含义
又称多表查询,当查询的字段来自于多个表时,就会用到连接查询
- 笛卡尔乘积现象: 表1 有m行,表2有n行,结果=m*n行。发生原因?没有有效的连接条件,如何避免?添加有效的连接条件分类
- 为表取别名: 提高语句的简洁度,区分多个重名的字段,需要注意的是:如果为表起了别名,则查询的字段就不能使用原来的表名去限定
# 6.2、分类
- 内连接
关键字:inner join
- 等值连接
- 非等值连接
- 自连接
- 外连接
关键字:left join、right join
- 左外连接
- 右外连接
- 全外连接(MySQL不支持)
- 交叉连接
关键字:cross join
用来返回连接表的笛卡尔积
# 6.3、语法
- inner join 内连接时,inner可以省略,默认 join 就是指内连接
select 字段, ...
from 表1
[inner|left outer|right outer|cross] join 表2 on 连接条件
[inner|left outer|right outer|cross] join 表3 on 连接条件
[where 筛选条件]
[group by 分组字段]
[having 分组后的筛选条件]
[order by 排序的字段或表达式]
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# 6.4、一图看懂多表连接
七种Join连接
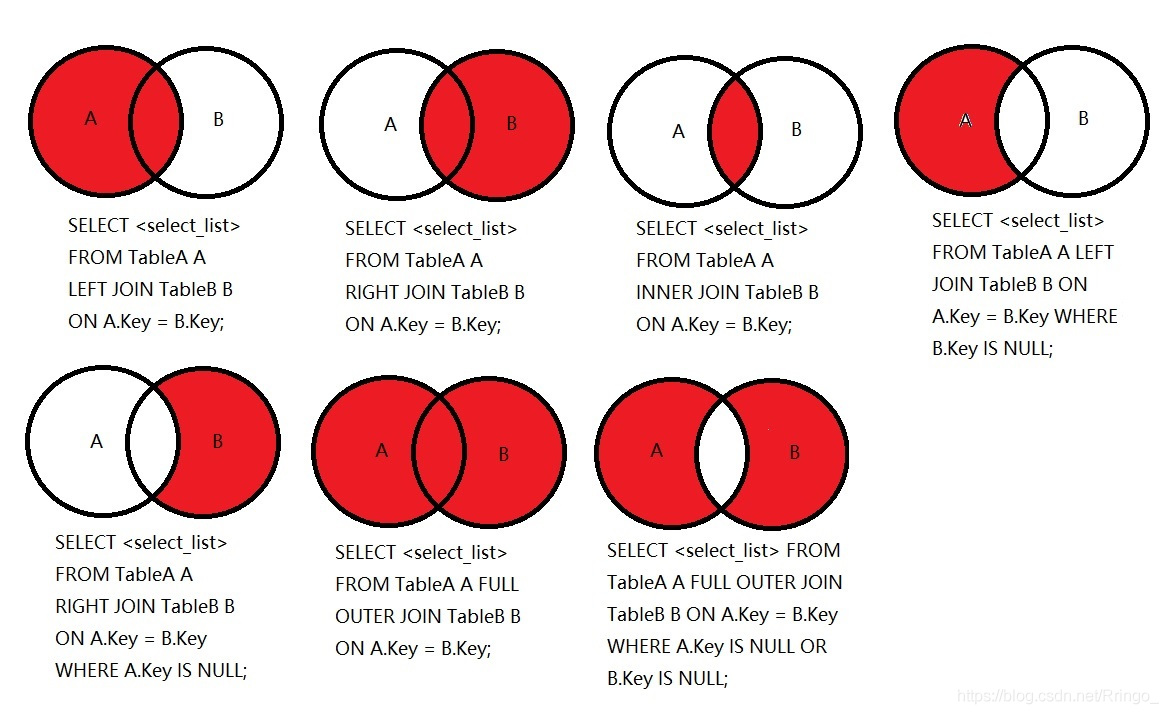
SQL代码实现:
/* 1 */
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key = B.Key;
/* 2 */
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key;
/* 3 */
SELECT <select_list> FROM TableA A INNER JOIN TableB B ON A.Key = B.Key;
/* 4 */
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key = B.Key WHERE B.Key IS NULL;
/* 5 */
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key WHERE A.Key IS NULL;
/* 6 */
-- SELECT <select_list> FROM TableA A FULL OUTER JOIN TableB B ON A.Key = B.Key;
/* MySQL不支持FULL OUTER JOIN这种语法 可以改成 1+2 */
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key = B.Key
UNION
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key;
/* 7 */
-- SELECT <select_list> FROM TableA A FULL OUTER JOIN TableB B ON A.Key = B.Key
-- WHERE A.Key IS NULL OR B.Key IS NULL;
/* MySQL不支持FULL OUTER JOIN这种语法 可以改成 4+5 */
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key = B.Key WHERE B.Key IS NULL;
UNION
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key WHERE A.Key IS NULL;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 7、子查询
含义
出现在其他语句中的select语句,称为子查询或内查询
子查询出现的位置
select后面
仅仅支持标量子查询
from后面
支持表子查询
where或having后面 ★
标量子查询(单行) ✔️
列子查询(单列多行) ✔️
行子查询 表子查询 (多列)
exists后面(相关子查询)
表子查询
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
特点
- 子查询放在小括号内
- 子查询一般放在条件的右侧
- 标量子查询,一般搭配着单行操作符使用
>、<、>=、<=、=、<>in、any/some、all- 列子查询,一般搭配着多行操作符使用
- 非相关子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果
例子
# () 中的就是子查询
select A.Key from A where A.Key in (select B.Key from B) ;
1
2
2
EXISTS(重要)
EXISTS
语法:SELECT...FROM tab WHERE EXISTS(subquery);
理解:将主查询的数据,放到子查询中做条件验证,根据验证结果(true或是false)来决定主查询的数据结果是否得以保留
注意点:
EXISTS(subquery)子查询只返回true或者false,因此子查询中的SELECT *可以是SELECT 1 OR SELECT X,它们并没有区别EXISTS(subquery)子查询的实际执行过程可能经过了优化而不是我们理解上的逐条对比,如果担心效率问题,可进行实际检验以确定是否有效率问题EXISTS(subquery)子查询往往也可以用条件表达式,其他子查询或者JOIN替代,何种最优需要具体问题具体分析
# 8、分页查询
语法
select 查询列表 from 表
join type join 表2 on 连接条件
where 筛选条件
group by 分组字段
having 分组后的筛选
order by 排序的字段】
limit 【offset,】size;
1
2
3
4
5
6
7
2
3
4
5
6
7
- offset要显示条目的起始索引(起始索引从0开始)
- size 要显示的条目个数
特点
- 起始条目索引从0开始
- limit子句放在查询语句的最后
- 公式:
select * from 表 limit (page-1)*pageSize, pageSize
pageSize:每页显示条目数page:要显示的页数
例子
#案例1:查询前五条员工信息
SELECT * FROM employees LIMIT 0, 5;
SELECT * FROM employees LIMIT 5;
#案例2:查询第11条——第25条
SELECT * FROM employees LIMIT 10, 15;
#案例3:有奖金的员工信息,并且工资较高的前10名显示出来
SELECT *
FROM employees
WHERE commission_pct IS NOT NULL
ORDER BY salary DESC
LIMIT 10;
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
# 9、联合查询
语法
查询语句1
union
查询语句2
union
...
查询语句n
1
2
3
4
5
6
2
3
4
5
6
特点
- 要求多条查询语句的查询列数是一致的
- 要求多条查询语句的查询的每一列的类型和顺序最好一致(不报错)
- union关键字默认去重,如果使用union all可以包含重复项
例子
#引入的案例:查询部门编号>90或邮箱包含a的员工信息
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;;
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90;
#案例:查询中国用户中男性的信息以及外国用户中年男性的用户信息
SELECT id,cname FROM t_ca WHERE csex='男'
UNION ALL
SELECT t_id,tname FROM t_ua WHERE tGender='male';
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
补充:UNION和UNION ALL的区别
区别1:取结果的并集
union: 对两个结果集进行并集操作, 不包括重复行,相当于distinct, 同时进行默认规则的排序;union all: 对两个结果集进行并集操作, 包括重复行, 即所有的结果全部显示, 不管是不是重复;
区别2:获取结果后的操作
union: 会对获取的结果进行排序操作;union all: 不会对获取的结果进行排序操作;
区别3:
- 相同查询SQL条件下,union all的执行效率要比union高