MySQL架构及存储引擎
半塘 2023/8/26 数据库MySQL
# 1、MySQL架构
# 1.1、MySQL架构图
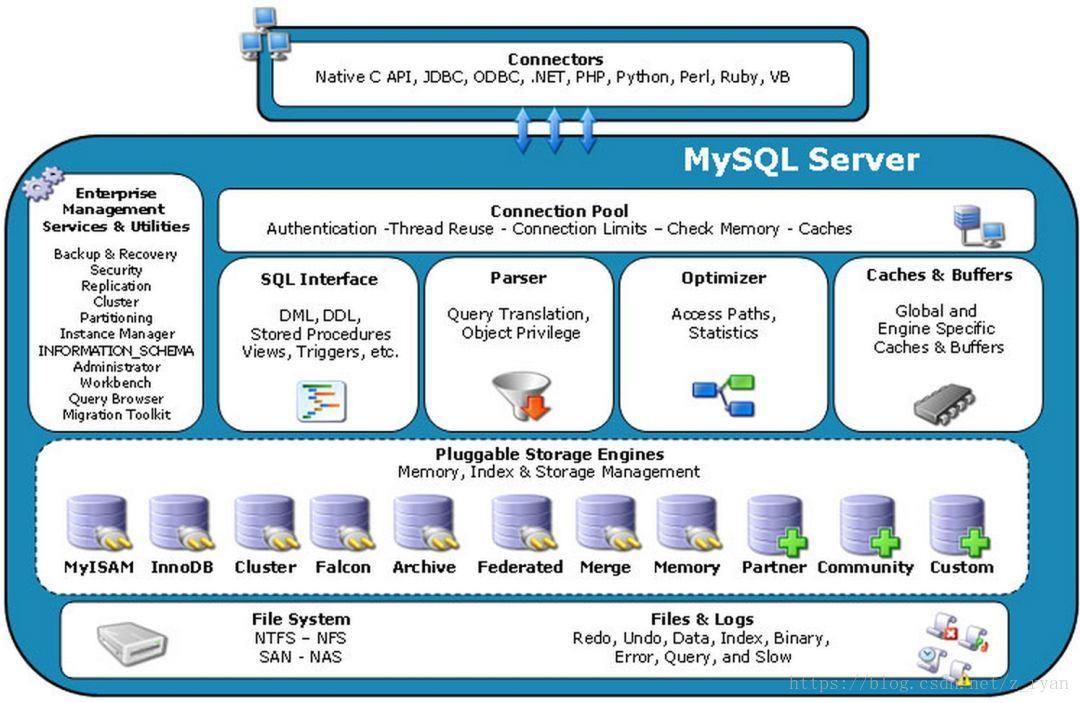
Connectors指的是不同语言中与SQL的交互,JDBC、Python、PHP等Connection Pool管理缓冲用户连接,线程处理等需要缓存的需求。MySQL数据库的连接层Management Serveices & Utilities系统管理和控制工具。备份、安全、复制、集群等等SQL Interface接受用户的SQL命令,并且返回用户需要查询的结果Parser SQL语句解析器Optimizer查询优化器,SQL语句在查询之前会使用查询优化器对查询进行优化。就是优化客户端请求query,根据客户端请求的 query 语句,和数据库中的一些统计信息,在一系列算法的基础上进行分析,得出一个最优的策略,告诉后面的程序如何取得这个 query 语句的结果。For Example:select uid,name from user where gender = 1;这个select查询先根据where语句进行选取,而不是先将表全部查询出来以后再进行gender过滤;然后根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤。最后将这两个查询条件联接起来生成最终查询结果Caches & Buffers查询缓存Pluggable Storage Engines存储引擎接口。MySQL区别于其他数据库的最重要的特点就是其插件式的表存储引擎(注意:存储引擎是基于表的,而不是数据库)File System数据落地到磁盘上,就是文件的存储
# 1.2、MySQL逻辑架构分层
和其他数据库相比,MySQL有点与众不同,主要体现在存储引擎的架构上,插件式的存储引擎架构将查询处理和其他的系统任务以及数据的存储提取相分离。这种架构可以根据业务的需求和实际需求选择合适的存储引擎
架构分层图:
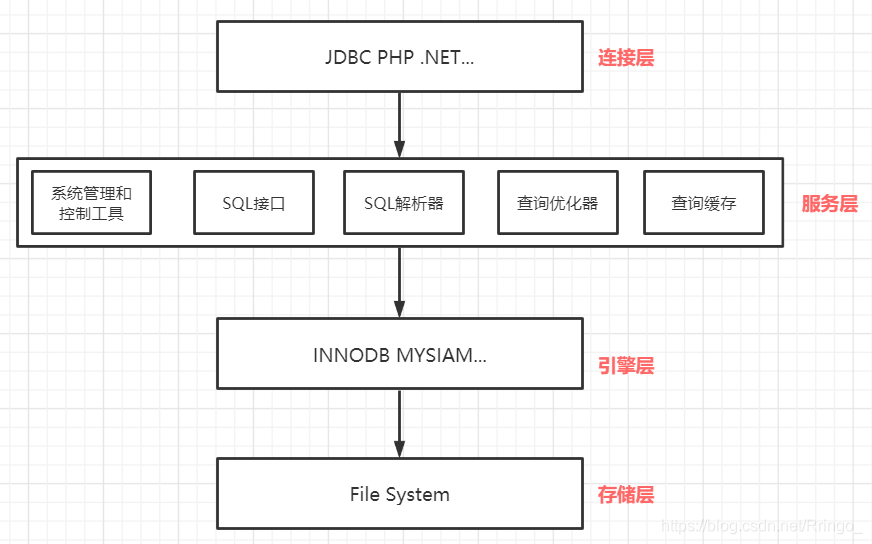
连接层: 最上层是一些客户端和连接服务,包含本地sock通信和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限
服务层: MySQL的核心服务功能层,是MySQL的核心,包括查询缓存,解析器,解析树,预处理器,查询优化器。主要进行查询解析、分析、查询缓存、内置函数、存储过程、触发器、视图等,select操作会先检查是否命中查询缓存,命中则直接返回缓存数据,否则解析查询并创建对应的解析树
引擎层: 存储引擎层,存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,可以根据自己的实际需要进行选取 存储层:数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互
# 1.3、MySQL运行机制
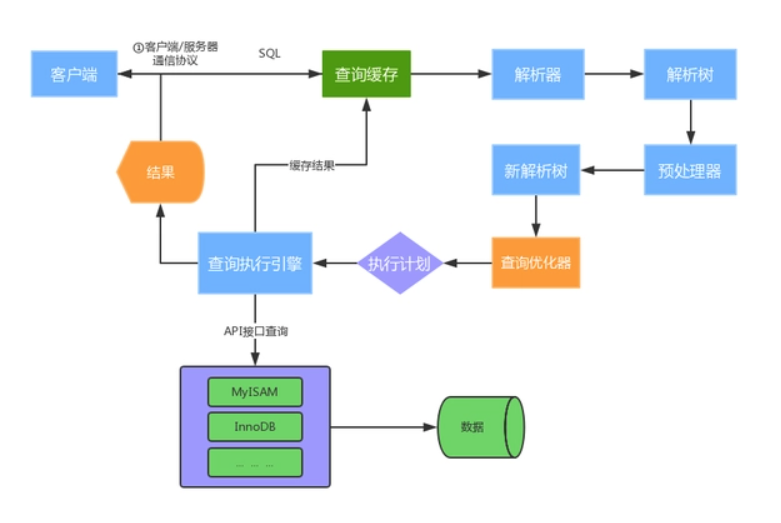
详细版

执行SQL过程
- 建立连接(Connectors&Connection Pool):通过客户端/服务器通信协议与MySQL建立连接。MySQL 客户端与服务端的通信方式是 “ 半双工 ”。对于每一个 MySQL 的连接,时刻都有一个线程状态来标识这个连接正在做什么。
- 查询缓存(Cache&Buffer):这是MySQL的一个可优化查询的地方,如果开启了查询缓存且在查询缓存过程中查询到完全相同的SQL语句,则将查询结果直接返回给客户端;如果没有开启查询缓存或者没有查询到完全相同的 SQL 语句则会由解析器进行语法语义解析,并生成“解析树”。
- 解析器(Parser):将客户端发送的SQL进行语法解析,生成"解析树"。预处理器根据一些MySQL规则进一步检查“解析树”是否合法,例如这里将检查数据表和数据列是否存在,还会解析名字和别名,看看它们是否有歧义,最后生成新的“解析树”。
- 查询优化器(Optimizer):根据“解析树”生成最优的执行计划。MySQL使用很多优化策略生成最优的执行计划,可以分为两类:静态优化(编译时优化)、动态优化(运行时优化)。
等价变换策略
- 5=5 and a>5 改成 a > 5
- a < b and a=5 改成b>5 and a=5
- 基于联合索引,调整条件位置等
- 优化count、min、max等函数
- InnoDB引擎min函数只需要找索引最左边
- InnoDB引擎max函数只需要找索引最右边
- MyISAM引擎count(*),不需要计算,直接返回
- 提前终止查询
- 使用了limit查询,获取limit所需的数据,就不在继续遍历后面数据
- in的优化,MySQL对in查询,会先进行排序,再采用二分法查找数据。比如where id in (2,1,3),变成 in (1,2,3)
- 查询执行引擎负责执行 SQL 语句:此时查询执行引擎会根据 SQL 语句中表的存储引擎类型,以及对应的API接口与底层存储引擎缓存或者物理文件的交互,得到查询结果并返回给客户端。若开启用查询缓存,这时会将SQL 语句和结果完整地保存到查询缓存(Cache&Buffer)中,以后若有相同的 SQL 语句执行则直接返回结果。
# 2、存储引擎
# 2.1、存储引擎相关命令
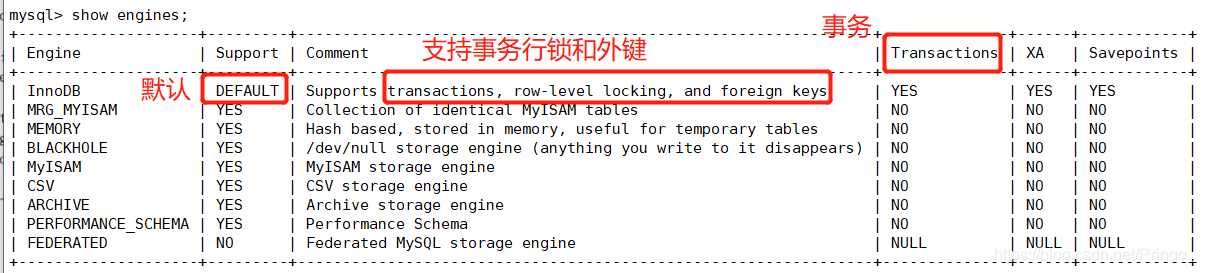
MySQL5.7支持命令查看存储引擎
# 查看存储引擎
mysql> show engines;
1
2
2
查询结果:
# 查看当前数据库正在使用的存储引擎
mysql> show variables like 'default_storage_engine%';
1
2
2
查询结果:

# 2.2、InnoDB和MyISAM对比
存储引擎是基于表的,而不是数据库。
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,即使操作一条记录也会锁住整张表,不适合高并发操作 | 行锁,操作时只锁某一行,不对其他行有影响,适合高并发操作 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引还要缓存真实数据,対内存要求较高,而且内存大小対性能有决定性影响 |
| 表空间 | 小 | 大 |
| 关注点 | 性能 | 事务 |
| 默认安装 | Y | Y |
# 3、SQL性能下降原因
- 查询语句写的差
- 索引失效:索引建了,但是没有用上
- 关联 查询太多join(设计缺陷或者不得已的需求)
- 服务器调优以及各个参数的设置(缓冲、线程数等)
# 4、SQL加载顺序
执行一条SQL的加载顺序从左到右
from > on > join > where > group by > having > select > distinct > order by > limit
1
sql执行加载解析图:

# 5、七种JOIN理论
Join连接:
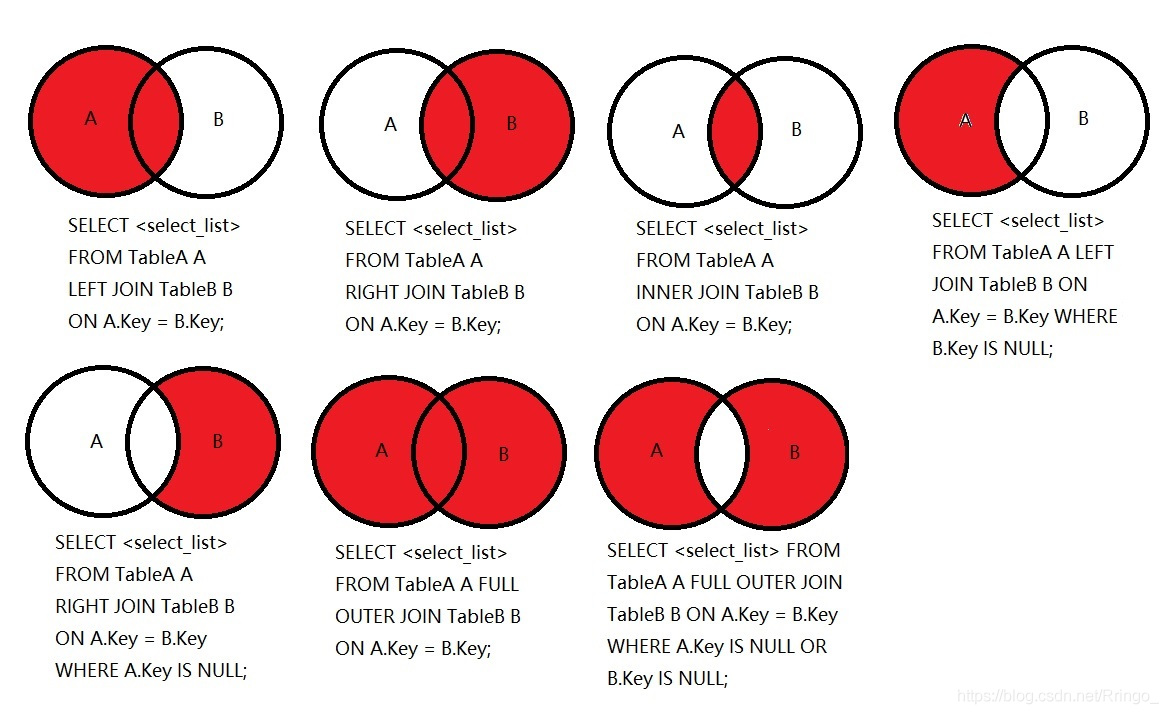
SQL代码实现:
/* 1 */
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key = B.Key;
/* 2 */
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key;
/* 3 */
SELECT <select_list> FROM TableA A INNER JOIN TableB B ON A.Key = B.Key;
/* 4 */
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key = B.Key WHERE B.Key IS NULL;
/* 5 */
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key WHERE A.Key IS NULL;
/* 6 */
-- SELECT <select_list> FROM TableA A FULL OUTER JOIN TableB B ON A.Key = B.Key;
/* MySQL不支持FULL OUTER JOIN这种语法 可以改成 1+2 */
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key = B.Key
UNION
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key;
/* 7 */
-- SELECT <select_list> FROM TableA A FULL OUTER JOIN TableB B ON A.Key = B.Key
-- WHERE A.Key IS NULL OR B.Key IS NULL;
/* MySQL不支持FULL OUTER JOIN这种语法 可以改成 4+5 */
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key = B.Key WHERE B.Key IS NULL;
UNION
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key WHERE A.Key IS NULL;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
补充:UNION和UNION ALL的区别
区别1:取结果的并集
union: 对两个结果集进行并集操作, 不包括重复行,相当于distinct, 同时进行默认规则的排序;union all: 对两个结果集进行并集操作, 包括重复行, 即所有的结果全部显示, 不管是不是重复;
区别2:获取结果后的操作
union: 会对获取的结果进行排序操作;union all: 不会对获取的结果进行排序操作;
区别3:
- 相同查询SQL条件下,union all的执行效率要比union高