分库分表
高并发,海量数据存储的解决方法有:缓存加速,读写分离,垂直拆分,分库分表,冷热数据分离,ES 辅助搜索,NoSQL 等方式,分库分表是海量数据存储与高并发系统的一个解决方案。 数据量大就分表,并发高就分库。
# 1、为什么要分库分表
- 如果是创业公司。比如注册用户20w, 每天日活1w, 每天单表1000, 高峰期每秒并发 10 ,这个时候,一般不需要考虑分库分表,如果注册用户2000w, 日活100w, 单表10w条,高峰期每秒并发1000,此时就要考虑分库分表。当然多加几台机器,使用负载均衡可以扛住,但是每天单表数据增加,磁盘资源会被消耗掉,高峰期如果要5000 怎么办,系统肯定撑不住。也就是说,数据增加,请求量增大,并发增大,单个数据库肯定不行。
- 单表数据量达到几十万或上百万以上,使用索引性能提升也不明显。
主要原因:单表数据量太大,数据查询、插入、更新性能都会降低。即使用上了最优的索引,也还是慢,一个数据库的IO和CPU的性能配置是有限的。
# 2、分表
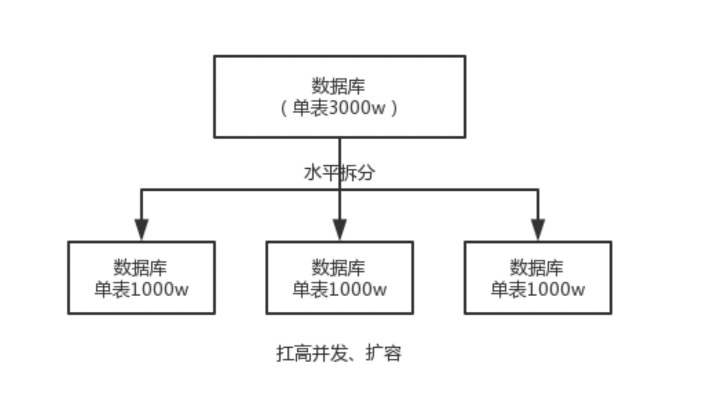
如果单表数据达到 几千万了,数据量比较大,会极大影响 SQL 查询性能, 后面的SQL 执行会很慢,经验来说,单表数据几百万,就要考虑分表了。 所谓的分表,就是将一个表的数据存放到多个表中, 查询的时候就查一个表。比如按照用户 id 来分表,将一个用户的数据存放在一个表中,然后对这个用户操作时操作那个表就好。一般来说,每个表的数据固定在 200w 以内比较好。
分表方式有两种
- 垂直拆分
- 水平拆分
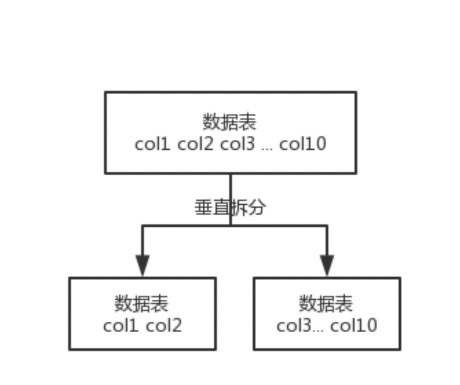
# 2.1、垂直拆分
所谓的垂直拆分,就是将一个表中的列拆分到多个表中,也就是说将一个大表拆分成多个小表。
如何分?
- 常用的列放在一个表,不常用的列放在其他表
- 关系紧密的列放在一个表
- 大字段列单独存放
坏处:
- 垂直分表引入的复杂性主要体现在表操作的数量要增加。例如,原来只要一次查询就可以获取 name、age、sex、nickname、description,现在需要两次查询,一次查询获取 name、age、sex,另外一次查询获取 nickname、description。
由于与业务关系密切,目前的分库分表产品均使用水平拆分方式
# 2.2、水平拆分
表结构保持不变, 对数据进行拆分,将表中对某些行拆分到其他表中。
如何分?常用的如下几种:
- 按时间拆分:每年的数据放一起,但是可能就会分配不均,因为每年数据量不一样。
- 按主键id范围拆分:1-100万 放一个表,100万-200万放一个表,以此类推。
- Hash分表:hash分表原理与hash表存储数据的原理类似,在hash表中,为了保证数据的均匀分布,在进行存储操作前需要对数据的关键字进行取模运算。比如:1%2=1(放1表),2%2=0(放0表)
# 3、分库
# 3.1、分表的遗留问题
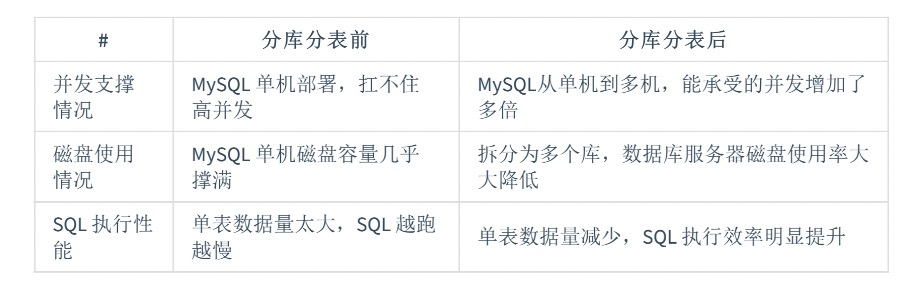
- 单纯的分表虽然可以解决数据量过大导致检索变慢的问题,但无法解决过多并发请求访问同一个库,导致数据库响应变慢的问题。所以通常水平拆分都至少要采用分库的方式,用于一并解决大数据量和高并发的问题。这也是部分开源的分片数据库中间件只支持分库的原因。
- 但分表也有不可替代的适用场景。最常见的分表需求是事务问题。同在一个库则不需考虑分布式事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。目前强一致性的分布式事务由于性能问题,导致使用起来并不一定比不分库分表快。目前采用最终一致性的柔性事务居多。分表的另一个存在的理由是,过多的数据库实例不利于运维管理。综上所述,最佳实践是合理地配合使用分库+分表。
分库, 经验来说,一个库对并发最多到 2000, 一定要扩容,一个健康的单库并发控制在1000 QPS 左右,如果超过,那么将一个库的数据拆分到多个库。
# 3.2、分表分表性能对比
分库+分表性能更佳
# 4、分库分表造成的问题
- join 操作:水平分表后,数据分散在多个表中,如果需要与其他表进行 join 查询,需要在业务代码或者数据库中间件中进行多次 join 查询,然后将结果合并。、
- count() 操作:水平分表后,虽然物理上数据分散到多个表中,但某些业务逻辑上还是会将这些表当作一个表来处理。例如,获取记录总数用于分页或者展示,水平分表前用一个 count() 就能完成的操作,在分表后就没那么简单了。
常见的处理方式有下面两种
- count() 相加:具体做法是在业务代码或者数据库中间件中对每个表进行 count() 操作,然后将结果相加。这种方式实现简单,缺点就是性能比较低。例如,水平分表后切分为 20 张表,则要进行 20 次 count(*) 操作,如果串行的话,可能需要几秒钟才能得到结果。
- 记录数表:具体做法是新建一张表,假如表名为“记录数表”,包含 table_name、row_count 两个字段,每次插入或者删除子表数据成功后,都更新“记录数表”。
- 问题:这种方式获取表记录数的性能要大大优于 count() 相加的方式,因为只需要一次简单查询就可以获取数据。缺点是复杂度增加不少,对子表的操作要同步操作“记录数表”,如果有一个业务逻辑遗漏了,数据就会不一致;且针对“记录数表”的操作和针对子表的操作无法放在同一事务中进行处理,异常的情况下会出现操作子表成功了而操作记录数表失败,同样会导致数据不一致,此外,记录数表的方式也增加了数据库的写压力,因为每次针对子表的 insert 和 delete 操作都要 update 记录数表。
- 解决方式:对于一些不要求记录数实时保持精确的业务,也可以通过后台定时更新记录数表。定时更新实际上就是“count() 相加”和“记录数表”的结合,即定时通过 count() 相加计算表的记录数,然后更新记录数表中的数据。
- order by 操作:水平分表后,数据分散到多个子表中,排序操作无法在数据库中完成,只能由业务代码或者数据库中间件分别查询每个子表中的数据,然后汇总进行排序。
# 5、分库分表技术实现
国内使用比较多的分库分表的中间件
- Apache ShardingSphere(推荐,京东、当当等大型互联网公司落地使用)
- Mycat(最近也比较火)
# 6、历史数据迁移
简单方案
比较简单同时也是非常常用的方案就是停机迁移,写个脚本老库的数据写到新库中。比如你在凌晨 2 点,系统使用的人数非常少的时候,挂一个公告说系统要维护升级预计 1 小时。然后,你写一个脚本将老库的数据都同步到新库中。
双写方案
- 我们对老库的更新操作(增删改),同时也要写入新库(双写)。如果操作的数据不存在于新库的话,需要插入到新库中。 这样就能保证,咱们新库里的数据是最新的。
- 在迁移过程,双写只会让被更新操作过的老库中的数据同步到新库,我们还需要自己写脚本将老库中的数据和新库的数据做比对。如果新库中没有,那咱们就把数据插入到新库。如果新库有,旧库没有,就把新库对应的数据删除(冗余数据清理)。
- 重复上一步的操作,直到老库和新库的数据一致为止。
- 要注意的是不允许老数据覆盖新数据。
想要在项目中实施双写还是比较麻烦的,很容易会出现问题,需要加入Canal做增量数据迁移。Canal可以参考:redis和mysql如何保持缓存一致性?阿里Canal告诉你 (opens new window)
操作步骤
- 增量数据监听 binlog,通过 canal 增量迁移数据
- 全量迁移历史数据
- 开启双写,关闭增量迁移任务。
- 读业务切换到新库
- 线上运行一段时间,没有问题后,下线老库。

参考: